ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی آیا تا به حال شده بخواهید یک وسیلهی سنگین را بلند کنید و یک نفره نتوانید این کار را انجام دهید؟ احتمالاً برای این کار از چند نفر کمک گرفتهاید و با کمکِ آنها، وسیلهی سنگین را بلند کردهاید. در واقع تکتکِ شما قدرتِ این را ندارید که این میز را بلند کنید، بنابراین از ترکیب کردنِ قدرتتان با یکدگیر برای انجامِ این کار استفاده میکنید. طبقهبندهای ترکیبی که به ensemble methods معروف هستند، همین کار را انجام میدهند. در این درس میخواهیم با مفهومِ طبقهبندهای ترکیبی و روشهای موردِ استفاده در آن صحبت کنیم.
طبقهبندهای ترکیبی از ترکیبِ چندین طبقهبند (classifier) استفاده میکنند. در واقع این طبقهبندها، هر کدام مدلِ خود را بر روی دادهها ساخته و این مدل را ذخیره میکنند. در نهایت برای طبقهبندیِ نهایی یک رایگیری در بین این طبقهبندها انجام میشود و آن طبقهای که بیشترین میزانِ رای را بیاورد، طبقهی نهایی محسوب میشود.
هر طبقهبند یک مدل را بر روی دادههای آموزشی میسازد تا به وسیلهی آن بتواند تفاوتها را در طبقههای مختلف درک کند. طبقهبندِ ترکیبی، اما به جای اینکه خود یک مدل بسازد از مدلهای ساخته شده توسطِ بقیهی طبقهبندها استفاده کرده و با یک رایگیری، مشخص میکند که کدام طبقه را برای نمونهی جاری باید برگزیند. شکلِ زیر یک نمونه از طبقهبندِ ترکیبی است:
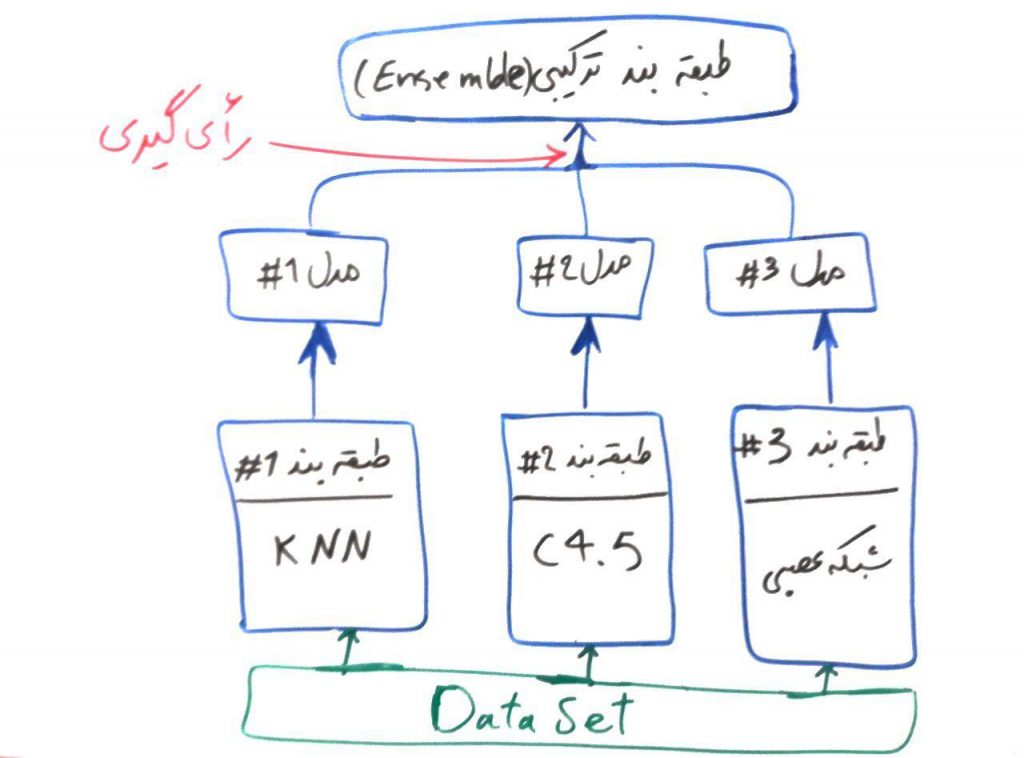
در شکل بالا، از سه الگوریتمِ پایه به نامهای KNN (نزدیک ترین همسایه)، درخت تصمیم C4.5 و شبکههای عصبی استفاده شده است. هر کدام از آنها توسط مجموعهی داده، یادگیری را انجام میدهند و مدلِ خود را میسازند. مثالِ پراید و اتوبوس را از دورهی شبکه عصبی به یاد بیاورید. فرض کنید این مجموعهی دادهی پراید و اتوبوس را به این سه الگوریتم دادهایم و هر کدام از این الگوریتمها، مدلِ خود را بر روی این مجموعهی داده ساختهاند. حال در این مثال یک نمونهی جدید که نمیدانیم پراید است یا اتوبوس به این سه الگوریتم داده میشود. مدلهای شمارهی ۱# و ۲# این نمونه را پراید طبقهبندی میکنند، این در حالی است که مدلِ شمارهی ۳# این نمونه را اتوبوس طبقهبندی میکند. پس الگوریتم ترکیبیِ نهایی، این مدل را بر اساس رایِ اکثریت (در اینجا ۲ به ۱)، در نهایت پراید طبقهبندی میکند.
پایهی الگوریتم های طبقه بندی ترکیبی (ensembleها) همان مثالی بود که در بالا گفتیم و اما دو روشِ معروف برای ساخت الگوریتمهای طبقهبندِ ترکیبی وجود دارند. bagging و boosting که در ادامه به آنها خواهیم پرداخت:
روش Bagging یا همان دستهبندی
همانطور که در شکل بالا مشاهده کردید، هر کدام از طبقهبندها، به مجموعهی داده (dataset) دسترسی دارند. در روش bagging یک زیر مجموعه از مجموعه دادهی اصلی به هر کدام از طبقهبندها داده میشود. یعنی هر طبقهبند یک قسمت از مجموعهی داده را مشاهده کرده و باید مدل خود را بر اساس همان قسمت از دادهها که در اختیارش قرار گرفته است، بسازد (یعنی کلِ دیتاست به هر کدام از طبقهبندها داده نمیشود). برای مثال شکل زیر را نگاهی بیندازید:
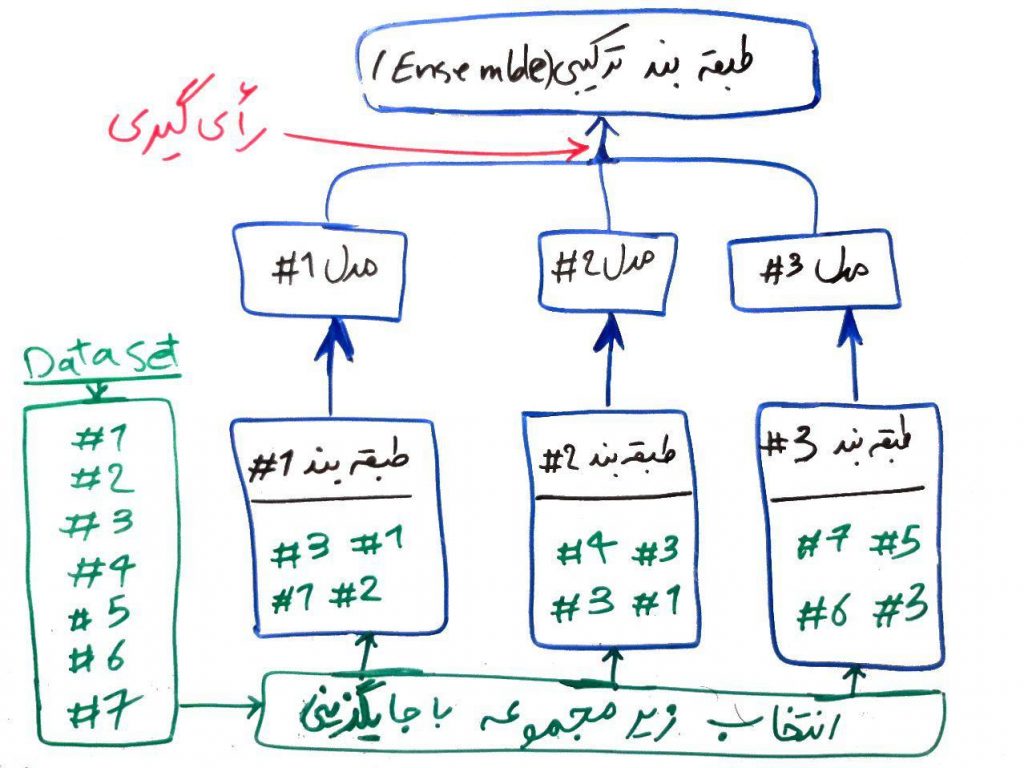
در این شکل، مجموعه دادهی ما دارای ۷ نمونه (مثلاً ۷ اتومبیل) است. برای هر کدام از طبقهبندها، یک زیرمجموعه از دادههای اصلی انتخاب میشود. انتخابِ این زیر مجموعه با جایگزینی خواهد بود. یعنی یک نمونه میتواند چند بار هم انتخاب شود. برای مثال به طبقهبند شماره ۱# نمونههای ۳، ۱، ۱ و ۲ داده شده است. همان طور که میبینید نمونه ۱ دو مرتبه به طبقهبندِ شمارهی ۱# داده شده است. طبق روال، هر طبقهبند با استفاده از دادههایی که در اختیار دارد یک مدل ساخته و بقیهی کار مانند مثالِ قبل انجام میشود. تحقیقات نشان داده است که روشِ bagging برای الگوریتمهایی مانندِ شبکههای عصبی یا درختهای تصمیم که با تغییرِ کمِ نمونهها ممکن است طبقههای مختلفی ایجاد کنند (این الگوریتم ها به الگوریتمهای غیرثابت (unstable) نیز شناخته میشوند) میتواند مفید باشد.