ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی یکی از الگوریتم های محبوب و مفید در این فن، الگوریتم FP-growth است. حجم داده ورودی FP-growth اصولا بسیار زیاد است و به همین دلیل یک محیط ابری چهارچوب مناسبی خواهد بود که میتواند از این حجم عظیم داده را به بخش های کوچکتر تقسیم و هر بخش را بصورت مجزا برای پردازش به یک نود خاص در شبکه ابری ارسال نمایید. این کار علاوه بر کاهش زمان اجرا تاثیر بسزائی در کاهش هزینه های ناشی از فراهم کردن بستره مورد نیاز برای داده کاوی خواهد داشت.
اگرچه الگوریتم کلاسیک و موجود FP-growth برای اجرا در معیارهای موازی طراحی نشده است و نیاز به انجام تغییراتی در الگوریتم هست. همچنین الگوریتم های موازی برای کاوش قوانین انجمنی نیز موجود هست کد پیاده سازی این الگوریتم ها به دلیل برخورد ارتباط پردازش و همگام سازی بسیار دشوار است. از طرف دیگر برطرف کردن شکست های پی در پی ناشی از محاسبات فراوان بسیار دشوار است. با توجه به تعاریف ذکر شده تصمیم گرفتم برای فن کاوش قواعد انجمنی داده کاوی در داده های حجیم در سرعت بیشتر و به صورت موازی، از الگوریتم FP-growth درون محیط رایانش ابری استفاده نماییم.
هدف اصلی من در این تحقیق بررسی کارایی و عملکرد الگوریتم FP-growth در محیط رایانش ابری و در مواجهه با مجموعه داده های حجیم است و همچنین مقایسه این الگوریتم با الگوریتم های پیاده سازی شده از لحاظ سرعت اجرا و کارایی از اهداف دیگر این تحقیق میباشد.
الگوریتم Fp-Growth:
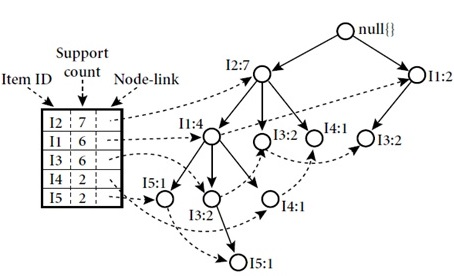
روش جالبی که مجموعه اقلام پرتکرار را بدون تولید مجموعه اقلام کاندید به دست میآورد، الگوریتم FP-Growth است که از یک استراتژی تقسیم وحل استفاده میکند. این روش پایگاه داده را به مجموعه ای از پایگاهداده ها که هرکدام یک قلم پرتکرار دارند، تقسیم میکند و هر پایگاه داده را جداگانه کاوش میکند.
در اوّلین اسکن پایگاه داده همانند اپریوری مجموعه آیتمهای یک عضوی و پشتیبانی آنها مشخص میشود. مجموعه اقلام پرتکرار به ترتیب نزولی پشتیبانیشان مرتّب میشوند.
سپس یک درخت به این صورت ساخته میشود که: اوّل ریشه درخت با برچسبnull ساخته میشود. بعد از آن پایگاه داده برای بار دوم اسکن میشود. اقلام هر تراکنش به ترتیب L پردازش میشوند و یک شاخه برای هر تراکنش ایجاد میشود.به منظور تسهیل پیمایش درخت، یک جدول ساخته میشود که هر قلم درآن به محلّ خودش در درخت اشاره میکند. درخت پس از اسکن همه تراکنش ها کامل میشود.
نگاشت – کاهش :
نگاشت – کاهش چهارچوبی برای پردازش موازی مسائل با حجم بالای داده با استفاده از تعداد زیادی کامپیوتر ( نود ) است. محاسبات میتواند بر روی داده های بدون ساختار مانند فایل ها و یا بر روی داده های ساختار یافته مانند پایگاه های داده اعمال شود. نگاشت – کاهش این مزیت را دارد که میتواند از داده به صورت محلی استفاده کند و پردازش را بر روی همان سامانه ای که ذخیره گاه هست و یا در نزدیکی همان سیستم اعمال کند و بدین ترتیب هزینه ی انتقال بین فواصل دور را کاهش دهد. در مراحل ی نگاشت ، نود مستر ورودی را گرفته آن را به زیر مسئله های کوچکتر تقسیم میکند و آن را به سمت نود های کارگر ارسال مینماید. نود کارگر نیز میتواند به نوبه ی خود همین کار را تکرار کند و به شکل یک ساختار درختی چند سطحی در بیاید هر نود کارگر مسئله ی کوچکتر منتسب به خود را حل کرده و جواب را به نود مستر خود برمیگرداند در مرحله ی کاهش ، نود مستر تمام جواب های مربوط به زیر مسئله ها را جمع آوری میکند و آن ها را به منظور شکل گیری خروجی نهایی به نحوی ادغام مینماید.
به بیان دقیقتر، نگاشت – کاهش در هر کلاستر شامل تنها یک نود مستر پیگیر JOB و یک نود کارگر پیگیر TASK است. نود مستر وظیفه ی تقسیم JOB به چندین TASK و ارسال آن به نود های کارگر ، کنترل آن ها و اجرای مجدد TASK هایی که با خطا مواجه شده اند را دارا میباشد. تعداد دفعات برای اجرای مجدد یک JOB قابل تنظیم است و نود های کارگر هر تعداد بار کد نود مستر از آن ها بخواهد یک TASK را انجام خواهد داد. چهارچوب نگاشت – کاهش منحصرا بر روی یک جفت < key.value > عمل میکند . این بدین معنیست که چهارچوب ورودی یک JOB را به صورت مجموعه ای از حقیقت های < key.value > میبیند و مجموعه ای از جفت های < key.value > را به عنوان خروجی JOB ایجاد مینماید. نیازی نیست که خروجی نگاشت و خروجی کاهش از یک نوع باشد. خروجی کاهش میتواند به عنوان رورودی یک تابع نگاشته دیگر ( متفاوت ) مورد استفاده قرار گیرد و بدین طریق الگوریتم نگاشت – کاهش طی چند مرحله کامل میشود.
یاده سازی الگوریتم fp-growth با متد نگاشت – کاهش
این الگوریتم را جهت موازی سازی و تقسیم همزمان کار بین سرورهای موجود در شبکه ابری با متد نگاشت – کاهش مینویسیم.
برای پیاده سازی الگوریتم fp-growth که به صورت سریال و برای اجرا بر روی یک نود نوشته شده است ، از کتابخانه متن بازی بنام SPMF استفاده میکنیم.این کتابخانه به زبان جاوا نوشته شده است و شامل پیاده سازی 75 الگوریتم مختلف داده کاوی میباشد.برای استفاده از این ماژولها تنها کافیست فایلهای آن شامل تمام ماژولها ، را درون پوشه کد برنامه خود قرار بدهیم و از توابع آن درون برنامه خود استفاده نماییم.قابل ذکر است که در میان تمام الگوریتمهای موجود در این کتابخانه ، الگوریتم fp-growth به عنوان سریعترین و کارامدترین الگوریتم از لحاظ استفاده از حافظه معرفی شده است .برای موازی سازی الگوریتم و امکان اجرا بر روی جندین نود از هدوپ استفاده میکنیم .هدوپ ورودی دریافت شده را به صورت تکه تکه در آورده و هر تکه را در یک سرور جداگانه ذخیره میکند.بخش mapreduce بر روی سرور اصلی اجرا میشود و بخش HDFS بر روی سرور های جانبی اجرا میگردد.سرورهای جانبی وظیفه ذخیره سازی اطلاعات را بر روی هارد دیسکهای خود بر عهده دارند.یعنی زمانی که یک کاربر دستور فراخوانی یک فایل را صادر میکند سرور اصلی از طریق آدرسهایی که در اختیار دارد بلاکهای مد نظر را از سرورهای مختلف فراخوانی کرده و پس از سر هم کردن و تکمیل کردن فایل ، آن را به کاربر تحویل میدهد .استفاده از هدوپ همچنین مزیت تکرار داده را دارد . الگوریتم این برنامه طوری نوشته شده است چندین نسخه کپی از بلاکها بر روی دیگر سرورها قرار میگیرند و این امر دو مزیت بزرگ دارد .اول اینکه در برابر خطاهای سخت افزاری از قبیل سوختن هارد دیسک ، اشکالات سخت افزاری سرورها و غیره محافظت میشود و در صورتی که هر یک ار سرورها به هر دلیلی از شبکه خارج شوند ، اطلاعات مورد نظر از روی سایر سرورها میتواند فراخوانی شود . مزیت دوم این است که دیگر نیازی به استفاده از تکنولوژیRAID نیست و میتوان از حد اکثر فضای هارد دیسک در هر سرور استفاده کرد. دو کلاس اصلی بنام های my mapper و my reducer و شش تابع اصلی run,run fp-growth, map,reduce, readfile,file-number طراحی و پیاده سازی شده است.
کلاس my mapper وظیفه مدیریت اجرای الگوریتم بر روی داده های توزیع شده بین نودها را بر عهده دارد.این کلاس ابتدا داده ها را گرفته و اقدام به تقسیم داده میکند سپس داده های تقسیم شده را در اختیار هدوپ قرار میدهد.هدوپ مجموعه داده را بر روی HDFS قرار میدهد سپس تابع run-fpgrowth را فراخوانی میکند. در انتها نیز تابع map جهت جمع آوری تمام نتایج فراخوانی میکند.
تابع run-fpgrowth که کار این تابع اجرای الگوریتم fp-growth بر روی داده های تخصیص داده شده به هر نود است .در این تابع از شی ALGO fp-growth یک نمونه ساخته میشود و سپس متد run algorithm این شی با سه پارامتر input , out put , minsup اجرا میشود.
تابع map تابعی است که ورودی اصلی را برای هدوپ به چند قسمت تقسیم میکند و در یک فایل میریزد و سپس بر روی فایل الگوریتم را اجرا میکند و در آخر خطوط داخل فایل متنی پاک میشود.
کلاس my reducerخروجی بدست آمده از هر نود هسته که به صورت موقت درون HDFS ذخیره میشود را جمع آوری و سپس تمام خروجیها را در یک فایل متنی ادغام میکند در نهایت خروجی نهایی در پوشه out put درون S3 بطور دایم ذخیره میشود.
تابع reduce که متن هر فایل را در خروجی نهایی ریخته و ذخیره میکند .
تابع run یه شی از متغیر job میسازد که در واقع همان myreduce است یک کلاس mapper یک کلاس reduce و یک کلاس کلی میگیرد .این تابع در حقیقت از برنامه میپرسد که چه فایلی را بگیرم ، چه عملیاتی بر روی آن انجام بدهم ور در انتها چه فایلی را به عنوان خروجی بدهم.همچنین دستور میدهد که برنامه هر کاری که در دو کلاس mapper و reduce قرار دارد را انجام دهد .در غیر اینصورت برنامه کاری انجام نخواهد داد.
تابع readfile خطهای ورودی را میخواند و تمام ورودی را به صورت آرایه های از فایلها در می آورد.
تابع file-number نیز تعداد خطوط ورودی را تعیین میکند و بر حسب تعداد نودها تعداد خطوط مشخصی را به هر نود اختصاص میدهد.استفاده از این الگوریتم در بهبود سرعت الگوریتم در محیط هدوپ کارامد خواهد بود.زیرا دیگر نیازی به مدیریت هدوپ جهت تقسیم داده نیست و این بخش سربار زمانی را کاهش خواهد داد.