ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی یادگیری تقویتی چیست و چگونه با روشهای یادگیری ماشین مرتبط میشود؟
«یادگیری تقویتی» (Reinforcement Learning | RL) گونهای از روشهای یادگیری ماشین است که یک «عامل» (agent) را قادر به یادگیری در محیطی تعاملی با استفاده از آزمون و خطاها و استفاده از بازخوردهای اعمال و تجربیات خود میسازد. اگرچه هم یادگیری نظارت شده و هم یادگیری تقویتی از نگاشت بین ورودی و خروجی استفاده میکنند، اما در یادگیری تقویتی که در آن بازخوردهای فراهم شده برای عامل مجموعه صحیحی از اعمال جهت انجام دادن یک وظیفه هستند، بر خلاف یادگیری نظارت شده از پاداشها و تنبیهها به عنوان سیگنالهایی برای رفتار مثبت و منفی بهره برده میشود.
یادگیری تقویتی در مقایسه با یادگیری نظارت نشده دارای اهداف متفاوتی است. در حالیکه هدف در یادگیری نظارت نشده پیدا کردن مشابهتها و تفاوتهای بین نقاط داده محسوب میشود، در یادگیری تقویتی هدف پیدا کردن مدل داده مناسبی است که «پاداش انبارهای کل» (total cumulative reward) را برای عامل بیشینه میکند. تصویر زیر ایده اساسی و عناصر درگیر در یک مدل یادگیری تقویتی را نشان میدهد.
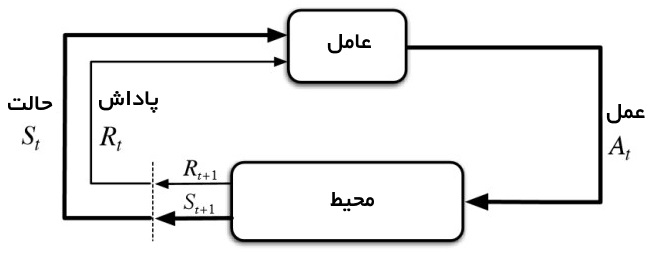
چگونه میتوان یک مساله پایهای یادگیری تقویتی را فرموله کرد؟
برخی از اصطلاحاتی که عناصر یک مساله یادگیری تقویتی را تشریح میکنند در ادامه بیان شده است.
- محیط (Environment): جهان فیزیکی که عامل در آن عمل میکند.
- حالت (State): موقعیت کنونی عامل
- پاداش (Reward): بازخورد از محیط
- سیاست (Policy): روشی برای نگاشت حالت عامل به عمل
- ارزش (Value): پاداش آینده که یک عامل با اقدام به یک عمل در یک حالت خاص به آن دست مییابد.
مسائل یادگیری تقویتی را میتوان به بهترین شکل از طریق بازیها تشریح کرد. از این رو، میتوان بازی «پَکمن» (PacMan) را مثال زد که در آن هدف عامل (پَکمن) خوردن خوراکیها (نقاط) موجود در هزارتو در حالی است که باید از روحهای موجود در آنجا دوری کند. دنیای شبکهای، یک محیط تعاملی برای عامل است. PacMan برای خوردن غذا پاداش دریافت میکند و در صورت کشته شدن توسط روح، تنبیه میشود (بازی را از دست میدهد). این حالتها موقعیت پَکمن در دنیای شبکهای هستند و پاداش انبارهای کل برابر با پیروزی پَکمن است.

به منظور ساخت یک سیاست بهینه، عامل با مساله جستوجوی حالتهای جدید در حالیکه پاداش را نیز به طور همزمان بیشینه میکند مواجه است. به این کار «موازنه جستوجو و استخراج» (Exploration vs Exploitation trade-off) گفته میشود. «فرآیندهای تصمیمگیری مارکوف» (Markov Decision Processes | MDPs) چارچوبهای ریاضی هستند که برای تشریح محیط در یادگیری تقویتی استفاده میشوند و تقریبا همه مسائل این حوزه قابل رسمی شدن با MDPها هستند.
یک MDP شامل مجموعهای متناهی از حالتهای محیط S، مجموعهای از اعمال ممکن (A(s در هر حالت، یک تابع پاداش دارای مقدار حقیقی (R(s و مدل انتقال (P(s’, s | a است. اگرچه، برای محیطهای جهان واقعی فقدان هرگونه دانش اولیهای از محیط وجود دارد. روشهای مستقل از مدل یادگیری تقویتی در چنین شرایطی مفید واقع میشوند.
Q-learning معمولا به عنوان یک رویکرد مستقل از مدل مورد استفاده قرار میگیرد و برای ساخت عامل پَکمن خودبازیکن قابل استفاده خواهد بود. این روش حول محور بهروز رسانی ارزشهای Q است که ارزش انجام عمل a را در حالت s نشان میدهد. قاعده بهروز رسانی ارزش، هسته الگوریتم Q-learning محسوب میشود.

پر استفادهترین الگوریتمهای یادگیری تقویتی کدام هستند؟
Q-learning و SARSA (سرنام State-Action-Reward-State-Action) دو الگوریتم محبوب و مستقل از مدل برای یادگیری تقویتی هستند. تمایز این الگوریتمها با یکدیگر در استراتژیهای جستوجوی آنها محسوب میشود در حالیکه استراتژیهای استخراج آنها مشابه است. در حالیکه Q-learning یک روش مستقل از سیاست است که در آن عامل ارزشها را براساس عمل a* که از سیاست دیگری مشتق شده میآموزد، SARSA یک روش مبتنی بر سیاست محسوب میشود که در آن ارزشها را براساس عمل کنونی a که از سیاست کنونی آن مشتق شده میآموزد. پیادهسازی این دو روش آسان است اما فاقد تعمیمپذیری هستند زیرا دارای توانایی تخمین ارزشها برای حالتهای مشاهده نشده نیستند.
با استفاده از الگوریتمهای پیشرفتهتری مانند Deep Q-Networks که از شبکههای عصبی برای تخمین Q-valueها استفاده میکنند میتوان بر این چالشها غلبه کرد. اما، DQNها تنها میتوانند فضای حالت گسسته و ابعاد کم را مدیریت کنند. DDPG (سرنام Deep Deterministic Policy Gradient) یک الگوریتم مستقل از مدل، مستقل از سیاست و عامل-نقاد (actor-critic) به شمار میآید که روش مواجهه آن با مساله، یادگیری سیاستهایی در فضای عمل ابعاد بالا و پیوسته است.