ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی روشهای انتخاب ویژگی (Feature Selection Methods) به منظور مواجهه با دادههای ابعاد بالا، به مولفهای جدایی ناپذیر از فرآیند یادگیری مبدل شدهاند. یک انتخاب ویژگی صحیح میتواند منجر به بهبود یادگیرنده استقرایی از جهتهای گوناگون از جمله سرعت یادگیری، ظرفیت تعمیم و سادگی مدل استنتاج شده شود. در این مطلب بحث استخراج ویژگی و انتخاب ویژگی و انواع روشهای آن مورد بررس قرار میگیرد.
چه ویژگی هایی استخراج کنیم؟ مشخصات ویژگی خوب چیست؟
ویژگی خوب باید سه شرط زیر را داشته باشد:
- Informative باشد. یعنی رابطه مستقیمی با خروجی داشته باشد، مثلا در تشخیص چهره دمای اتاق یا رنگ پیراهن هیچ ربطی به خروجی ندارند و نباید استخراج شوند.
- Discriminant باشد. ویژگی باید مقادیر متفاوتی بین کلاس ها داشته باشد. در حالت کلی ویژگی خوب ویژگی ای است که واریانس درون کلاسی آن حداقل(یعنی بین نمونه های مشابه مقدار یکسان و یا نزدیکی بهم داشته باشند) و واریانس بین کلاسی آن حداکثر(بین نمونه های سایر کلاسهاد مقدارمتفاوتی داشته باشند) داشته باشند.
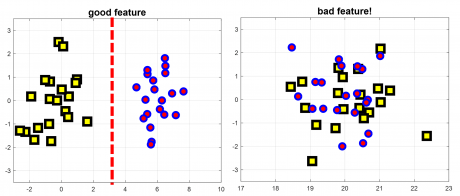
- ویژگی ها از هم مستقل باشند. ویژگی ها اگر مستقل نباشند درواقع بحث افزونگی یا همان redundacy پیش می آید که باعث کاهش عملکرد سیستم می شود. ما ممکن است ویژگی های خوبی استخراج کنیم، ولی این ویژگی ها کنار هم اصلا نمیتوانند خوب عمل کنند و در نتیجه کارایی مدل کاهش می یابد.
چطور ویژگی خوب استخراج کنیم؟
استخراج ویژگی یکی از مهمترین مراحل یادگیری ماشین است و اگر ما ویژگی خوبی استخراج نکنیم، الگوریتم تصمیم گیرنده ما هرچقدر هم که خوب باشد نمی تواند عملکرد خوبی داشته باشد! پس باید حوسمان باشد که ویژگی های خوبی به مدل تصمیم گیرنده ارائه بدهیم. ولی خب سوال اینجاست که من چگونه ویژگی خوب استخراج کنم؟؟ جواب: گوناگون(مزاح بود)
ما خودمان به سختی میتوانیم یک ویژگی خوب را تشخیص دهیم. در یادگیری ماشین، الگوریتمهایی داریم که کارشان تشخیص ویژگی خوب هست، پس تا جایی که میتوانید شما ویژگی استخراج کنید و کاری به خوب یا بد بودن آن نداشته باشید، در واقع کورکورانه هر ویژگی ای که میتوانید استخراج کنید بعدا این الگوریتمهای انتخاب ویژگی، ویژگی های خوب را انتخاب کرده و به کلاسبند ارائه میدهند. در یادگیری ماشین برای تشخیص چهره و یا هر تسک شناسایی چه سیگنال و چه تصویر از مدل زیر استفاده میکنند که در جلسه بعدی مفصل در مورد این بخش توضیح خواهم داد.
طی چند سال اخیر، مجموعه دادههای متعددی با ابعاد بالا در اینترنت در دسترس عموم قرار گرفتند. این امر چالش جالب توجهی را برای جوامع پژوهشی در پی داشت، زیرا برای الگوریتمهای یادگیری ماشین سر و کار داشتن با حجم زیادی از ویژگیهای ورودی کاری دشوار است. در حال حاضر، ابعاد مجموعه دادههای بنچمارک که از مخازن داده گوناگون در دسترس هستند به میلیونها عدد یا حتی بیشتر افزایش یافته است. در حقیقت، تحلیلهایی که توسط پژوهشگران انجام شده حاکی از آن است که ۷ تا از ۱۱ مجموعه دادهای که در سال ۲۰۰۷ منتشر شدهاند دارای ابعادی بالغ بر میلیونها ویژگی بودهاند. برای مواجهه با مساله تعداد بالای ویژگیها، روشهای کاهش ابعاد الزامی است و میتوانند به بهبود کارایی یادگیری کمک کنند.
اصطلاح «ابعاد کلان» (Big Dimensionality) برای اشاره به مشکل مذکور استفاده میشود و در قیاس با واژه «کلان داده» (مِه داده | Big Data) که با حجم نمونههای بالا سر و کار دارد، ساخته شده است. روشهای کاهش ابعاد اغلب در دو دسته انتخاب ویژگی و استخراج ویژگی قرار دارند و هر یک از آنها دارای خصوصیات ویژه خود هستند. از یک سو، روشهای استخراج ویژگی با ترکیب ویژگیهای اصلی به کاهش ابعاد دست مییابند. از این رو، قادر به ساخت مجموعهای از ویژگیهای جدید هستند که معمولا فشردهتر و دارای خاصیت متمایزکنندگی بیشتری است. این روشها در کاربردهایی مانند تحلیل تصویر، پردازش تصویر و بازیابی اطلاعات (information retrieval) ترجیح داده میشوند زیرا در این موارد صحت مدل از تفسیرپذیری آن بیشتر حائز اهمیت است.
انتخاب ویژگی
انتخاب ویژگی را میتوان به عنوان فرآیند شناسایی ویژگیهای مرتبط و حذف ویژگیهای غیر مرتبط و تکراری با هدف مشاهده زیرمجموعهای از ویژگیها که مساله را به خوبی و با حداقل کاهش درجه کارایی تشریح میکنند تعریف کرد. این کار مزایای گوناگونی دارد که برخی از آنها در ادامه بیان شدهاند.
- بهبود کارایی الگوریتمهای یادگیری ماشین
- درک داده، کسب دانش درباره فرآیند و کمک به بصریسازی آن
- کاهش داده کلی، محدود کردن نیازمندیها ذخیرهسازی و احتمالا کمک به کاهش هزینهها
- کاهش مجموعه ویژگیها، ذخیرهسازی منابع در دور بعدی گردآوری داده یا در طول بهرهبرداری
- سادگی و قابلیت استفاده از مدلهای سادهتر و کسب سرعت
به همه دلایل گفته شده، در سناریوهای «تحلیل کلان داده»، انتخاب ویژگی نقشی اساسی ایفا میکند.
ویژگی مرتبط
برای تشخیص یک «ویژگی مرتبط» (Feature Relevance) با مساله، از این تعریف استفاده میشود: «یک ویژگی مرتبط است اگر شامل اطلاعاتی پیرامون هدف باشد». به بیان رسمیتر، «جان» (John) و کوهاوی (Kohavi) ویژگیها را به سه دسته جدا از هم تقسیم کردهاند که «به شدت مرتبط» (strongly relevant)، «به طور ضعیف مرتبط» (weakly relevant) و «ویژگی غیرمرتبط» (irrelevant features) نامیده میشوند.
افزونگی ویژگی
یک ویژگی معمولا در صورت وجود همبستگی بین ویژگیها دارای افزونگی (Feature Redundancy) محسوب میشود. این مفهوم که دو ویژگی نسبت به هم دارای افزونگی هستند اگر مقادیر آنها کاملا همبسته باشد توسط پژوهشگران زیادی پذیرفته شده، اما در عین حال امکان دارد تشخیص افزونگی ویژگیها هنگامی که یک ویژگی با یک مجموعه از ویژگیها مرتبط است کار سادهای نباشد.
مطابق با تعریف ارائه شده توسط جان و کوهاوی، یک ویژگی در صورتی دارای افزونگی است و در نتیجه باید حذف شود که به طور ضعیف مرتبط و دارای پوشش مارکوف (Markov blanket) درون مجموعه ویژگیهای کنونی باشد. از آنجا که ویژگیهای غیرمرتبط باید به هر سو حذف شوند، پاکسازی آنها بر اساس این تعریف انجام میشود.
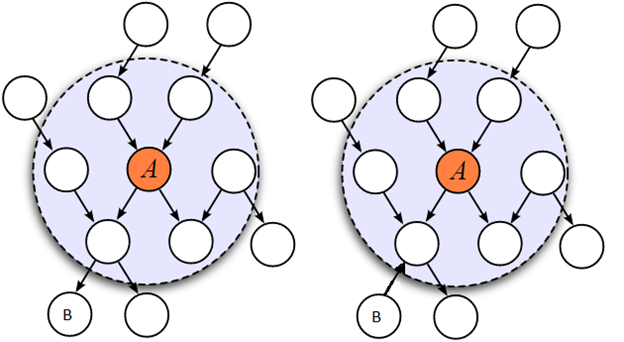
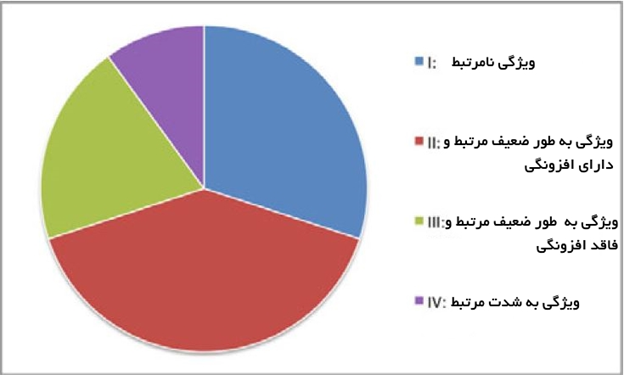
در شکل زیر چشماندازی از ارتباط بین ارتباط ویژگیها و افزونگی ارائه شده است. کل مجموعه ویژگی میتواند به طور مفهومی به چهار بخش مجزا تقسیم شود که عبارتند از ویژگیهای نامرتبط (I)، ویژگیهای به طور ضعیف مرتبط و ویژگیهای دارای افزونگی (II)، ویژگیهای به طور ضعیف مرتبط ولی فاقد افزونگی (III) و ویژگیهای به شدت قدرتمند (IV). لازم به ذکر است که مجموعه بهینه حاوی همه ویژگیهای موجود در بخشهای III و IV میشود.