ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی الگوریتمِ جستجوی ممنوعه یک ایدهی اصلی دارد. این الگوریتم یک لیست از حرکات یا نقاطِ ممنوعه درست میکند تا در جستجوهای بعدی، دیگر آن حرکات را انجام ندهد. با این کار این الگوریتم امید دارد که از بهینهی محلی خارج شده و بتواند به سمت بهینهی سراسری حرکت کند.
برای درک بهتر، فرض کنید شما یک فروشندهی موبایل هستید که میخواهید حداکثرِ سود را از فروش موبایل انجام دهید. برای اینکار بایستی راههای مختلفِ فروش را امتحان کنید. اجازه بدهید مسئله را ساده کنیم. شما به عنوان فروشنده با خود قرار میگذارید تا اگر یک شخص جوان به سراغ مغازهی شما آمد، موبایل با یکی از رنگها را به او پیشنهاد دهید. حال فرض کنید یک شخص جوان به فروشگاهِ شما وارد شد. شما موبایل با رنگ قرمز را به او پیشنهاد میدهید. با این کار پیشنهادِ موبایل با رنگ قرمز در لیست ممنوعه (Tabu list) قرار میگیرد و شما تا یک زمان مشخص (مثلاً تا ۳مشتریِ دیگر) به هیچ شخصی موبایل قرمز پیشنهاد نمیدهید، چون پیشنهاد موبایل قرمز از حالا به بعد در لیستِ ممنوعه قرار دارد. این کار باعث میشود که شما پیشنهادِ رنگهای دیگر را نیز به مشتریان امتحان کنید. با این کار شما میتوانید رنگهای مختلف را به مشتریانِ متفاوت پیشنهاد بدهید و در واقع از یک بهینهی محلی خارج شوید و راههای دیگر کسبِ درآمد را امتحان کنید (ایدهی اصلی در الگوریتمهای فراابتکاری همین است). البته این کار یک نکته دارد. فرض کنید پیشنهادِ رنگ قرمز همچنان در لیست ممنوعه باشد (یعنی نباید به مشتریِ بعدی رنگ قرمز را پیشنهاد دهید) ولی یک مشتری با کیفِ قرمز و ماشینِ قرمز و ساعتِ قرمز رنگ وارد مغازه میشود. شما میدانید که بر اساس تکنیکهای فروش، بایستی موبایل با رنگ قرمز را به او پیشنهاد بدهید و با این کار احتمالِ خریدِ او بالاتر میرود. پس با وجود اینکه رنگِ قرمز در لیست ممنوعه قرار دارد، به خاطرِ احتمالِ خریدِ بسیار بالاتر، شما قانونِ لیستِ ممنوعه را نقض میکنید و موبایل با رنگ قرمز را به او پیشنهاد میدهید. به این شرایط در اصطلاح در الگوریتم جستجوی ممنوعه، شرایط تنفس (Aspiration Criterion) میگویند، یعنی شرایطی که به خاطرِ خوب بودنِ زیاد، شما قانونِ لیست ممنوعه را نقض میکنید.
از مثال بالا متوجه شدید که جستجوی ممنوعه، دو عنصر اصلی دارد. لیست ممنوعه (Tabu List) و شرایط تنفس (Aspiration Criterion) که تحقیقات نشانداده است با استفاده از این دو قاعدهی ساده، میتواند به نتایج خوبی دست پیدا کند.
حالا اجازه بدهید، با یک مثالِ دیگر بحث را بیشتر جا بیندازیم. فرض کنید یک پردازنده (CPU) میخواهد یک سری وظیفه (Task) را به ترتیب انجام دهد. این سری وظایف در کنارِ هم، یک زمانبند (Scheduler) را میسازند. هر کدام از ترتیبهای این وظایف با سرعتهای مختلفی انجام میشوند و ترتیبِ آنها در سرعتِ اجرا تاثیرگذار است. برای مثال اگر وظیفهی شماره ۱ بعد از وظیفهی شماره ۳ انجام شود، سرعتِ اجرای آن زمانبند بهتر میشود. در نهایت CPU میخواهد بداند که کدام ترتیبِ وظایف (یعنی کدام زمانبند) با سرعت بیشتری اجرا میشود. شکل زیر را نگاه کنید:
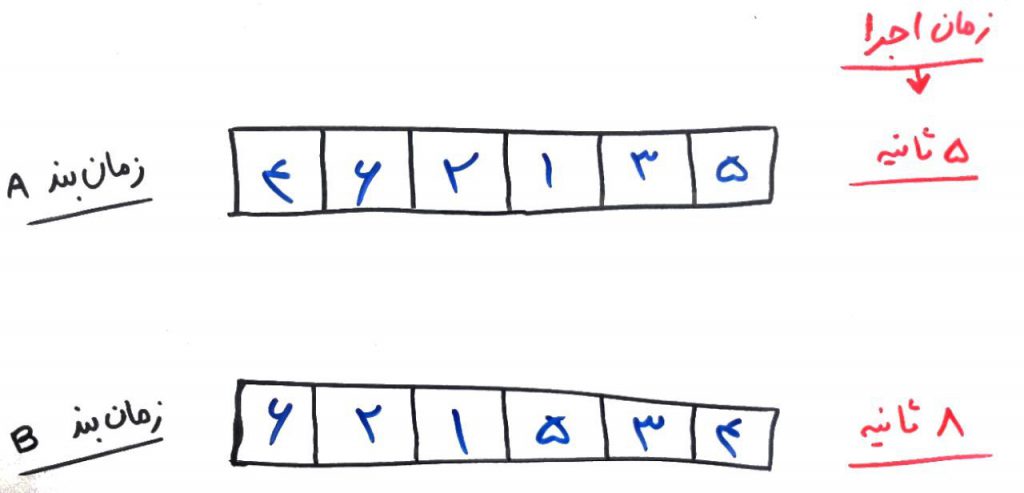
وظایف با شمارههای ۱ تا ۶ نامگذاری شدهاند. هر کدام از خانهها یک وظیفه (Task) است و وظیفههایی که سمت چپتر آمدهاند، زودتر انجام میشوند. برای مثال در جدول A، ابتدا وظیفهی ۴ و بعد وظیفهی ۶ و سپس وظیفهی ۲ و به همین ترتیب تا آخر انجام شده است. هر کدام از این زمانبندیها، باعثِ تغییر در سرعت اجرای مجموعهی وظایف میشود. در شکلِ بالا، زمانبندی مطابق با جدولِ A، در زمان ۵ ثانیه انجام شد و زمانبندی مطابق با جدولِ B در زمان ۸ ثانیه. مسلم است که زمانبندیِ A بهتر از زمانبندیِ B است (زمانبندیِ A بهینهتر است).
در مثالِ بالا، میخواهیم یک زمانبندیِ بهینه (یا نزدیک به بهینه) را در زمانی معقول پیدا کنیم. برای اینکار بایستی تمامیِ حالات و جابهجاییها را انجام داده و سرعتِ هر کدام را اندازه بگیریم. اگر بخواهیم تمامیِ حالات را جستجو کنیم بایستی تمامیِ جایگشتها را برای این ۶ وظیفه پیدا کنیم. یعنی نیاز به !۶ (۶ فاکتوریل) حالت یعنی ۷۲۰ بار محاسبه داریم. فرض کنید CPU برای هر بار محاسبهی زمان، نیاز به ۱ ثانیه زمان داشته باشد. پس بایستی ۷۲۰ ثانیه برای به دست آوردنِ بهترین حالت صبر کند (تا تمامیِ جایگشتها را ایجاد کرده و هر سرعتِ هر کدام را تست کند). در حالیکه در بسیاری از کاربردها (مثلاً برای Queryهای پایگاه داده) این زمان بسیار زیاد است. پس بایستی الگوریتمی توسعه داده شود که بدون جستجو در تمامیِ حالات، بتواند با یک سری جستجوی محدود و یک سری حالاتِ محدود، جواب بهینه (یا نزدیک به بهینه) برسد. این همانکاری است که الگوریتمهای فراابتکاری برای حلِ مسئله انجام میدهند.
حالا میخواهیم مسئلهی زمانبندیِ ۶ وظیفهای را با الگوریتمِ جستجوی ممنوعه (Tabu Search) حل کنیم. ابتدا یک راهحل اولیه تولید میکنیم (مثلاً به صورت تصادفی وظایف را در یک زمانبند قرار میدهیم) چیزی مانند شکل زیر:
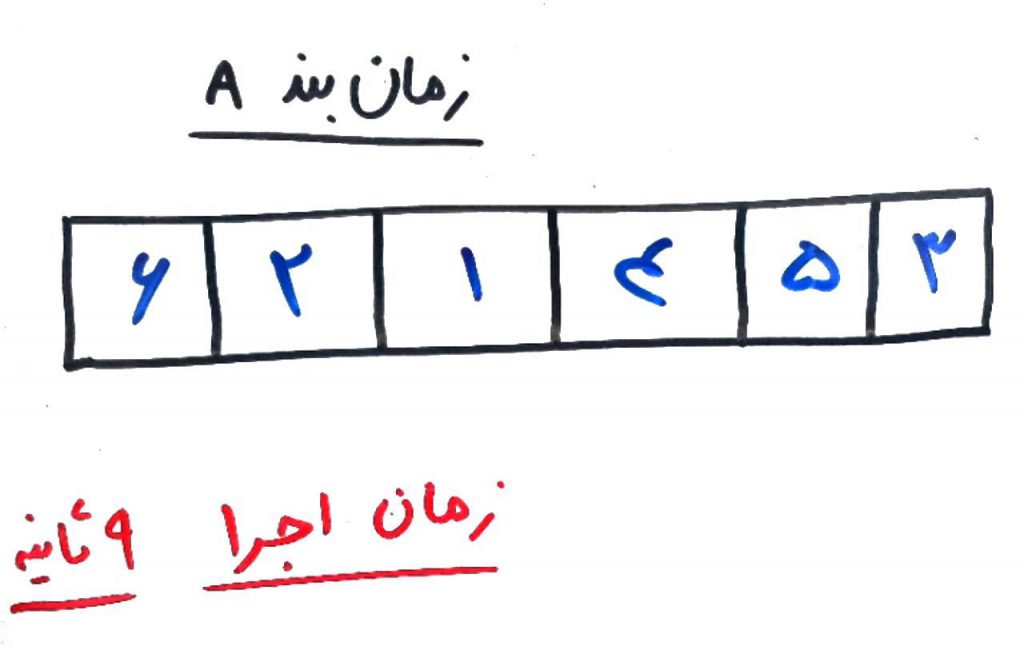
همانطور که میبینید این ترتیب زمانی از اجرای وظیفهها (Tasks) توسط CPU، به اندازهی ۹ثانیه زمان نیاز دارد. یعنی اگر وظیفهی شمارهی ۶ ابتدا انجام شود و بعد وظیفهی ۲ و بعد ۱ و بعد ۴ و ۵ و ۳، همهی این وظایف با هم به ۹ ثانیه زمان برای اجرا نیاز دارند. حال بایستی یک وضعیتِ همسایه را برای این حالت پیدا کنیم. وضعیتِ همسایه به وضعیتی میگویند که بسیار نزدیک به وضعیتِ فعلی است. با این کار شاید دیگر نیاز نباشد که محاسبات را از اول انجام دهیم.