 ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی بردار پشتیبان
ماشین بردار پشتیبان دستهبندی کنندهای است که جزو روشهای بر پایه هسته در یادگیری ماشین محسوب میشود. SVM در سال 1992 توسط وپنیک معرفی شده و بر پایه نظریه آماری یادگیری بنا گردیده است. الگوریتم SVM یکی از الگوریتمهای معروف در زمینه یادگیری با نظارت است که برای دستهبندی و رگرسیون استفاده میشود. این الگوریتم به طور همزمان حاشیههای هندسی را بیشینه کرده و خطای تجربی دستهبندی را کمینه میکند لذا به عنوان دستهبندی حداکثر حاشیه نیز نامیده میشود.
برای یک مسأله دستهبندی با دو دسته نتیجه خطوط بیشماری ممکن است وجود داشته باشند که توسط آنها دستهبندی انجام شود ولی فقط یکی از این خطوط ماکزیمم تفکیک و جداسازی را فراهم میآورد. از بین جداسازهای خطی، آن جداسازی که حاشیه دادههای آموزشی را حداکثر میکند خطای تعمیم را حداقل خواهد کرد. نقاط دادهای ممکن است ضرورتاً نقاط دادهای در فضای R2 نباشند و ممکن است در فضای چند بعدی Rn مربوط باشند. دستهبندهای خطی بسیاری ممکن است این خصوصیت را ارضا کنند اما SVM به دنبال جداکنندهای است که حداکثر جداسازی را برای دستهها انجام دهد.
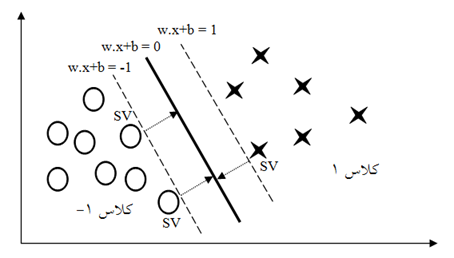
همانطور که در شکل (8-2) مشاهده میشود فراصفحههایی که از نزدیکی دادههای آموزش میگذرند حساس به خطا میباشند و احتمال اینکه برای دادههای خارج از مجموعه آموزش قدرت تعمیم دهی خوبی داشته باشند بسیار کم است. در عوض، به نظر میرسد فراصفحه ای که بیشترین فاصله را از تمام نمونههای آموزشی دارد قابلیتهای تعمیم دهی مناسبی را فراهم آورد. نزدیکترین دادههای آموزشی به فراصفحههای تفکیک کننده را بردار پشتیبان (SV ) نامیده میشوند. اگر مجموعه داده به صورت {(Xn,Yn),…,(X2,Y2),(X1,Y1)} نشان داده شود. Yi میتواند مقدار 1 و 1- دریافت کند که توسط این ثابتها دستههای نقاط Xi مشخص میگردد که هر Xi یک بردار n بعدی است. هنگامی که دادههای آموزشی که در دستههای صحیح دستهبندی شدهاند را در اختیار داریم، SVM توسط تقسیمبندی فراصفحه ای آنها را از هم جدا کرده و در دستههای جداگانه قرار میدهد به طوری که WTX+d=0 , بردار W نقاط عمودی فراصفحهها را جدا میکند و b میزان حاشیه را مشخص میکند. فراصفحههای موازی را میتوان به صورت W.X+d=1 و W.X+d=-1 تعریف کرد.
اگر دادههای آموزشی به صورت خطی جدایی پذیر باشند، میتوان فراصفحهها را به طوری انتخاب نمود که هیچ نمونهای میان آنها نباشد و سپس تلاش کرد تا فاصله آنها را به حداکثر رسانید. برای هر نمونه i از دادهها رابطه زیر را داریم:

میتوان تصور کرد SVM بین دو دسته داده صفحهای را ترسیم میکند و دادهها را در دو طرف این صفحه تفکیک مینماید. این فراصفحه به گونهای قرار میگیرد که ابتدا دو بردار از یکدیگر دور میشوند و به گونهای حرکت میکنند که هر یک به اولین داده نزدیک به خود برسد. سپس صفحهای که در میان حد واسط این دو بردار رسم میشود از دادهها حداکثر فاصله را خواهد داشت و تقسیم کننده بهینه است.
تا اینجا، با این فرض که نمونههای آموزشی به صورت خطی جدایی پذیرند به استفاده از الگوریتم ماشین بردار پشتیبان پرداختیم. همانطور که میدانیم در عمل توزیع دادههای دستههای مختلف ممکن است به راحتی جدایی پذیر نبوده و دارای تداخل باشد . در این صورت، تفکیک سازی دقیق نمونهها ممکن است سبب تعمیم دهی ضعیف گردد.
یک راه حل این است که مقداری خطا در دستهبندی را بپذیریم. این کار با معرفی متغیر بی دقت (ξi) انجام میشود که نشانگر نمونههایی است که توسط تابع WTX+d=0 غلط ارزیابی میشوند. این روش که به SVM با حاشیهی نرم معروف است که اجازه میدهد بعضی از نمونهها در ناحیه اشتباه قرار گیرند سپس آنها را جریمه میکند؛ لذا این روش برخلاف SVM حاشیهی سخت برای مواردی که نمونههای آموزشی به صورت خطی جدایی پذیر نیستند قابل استفاده است.
با معرفی متغیر ξi محدودیتهای قبلی سادهتر شده و رابطه (2-7) به صورت زیر تغییر میکند:
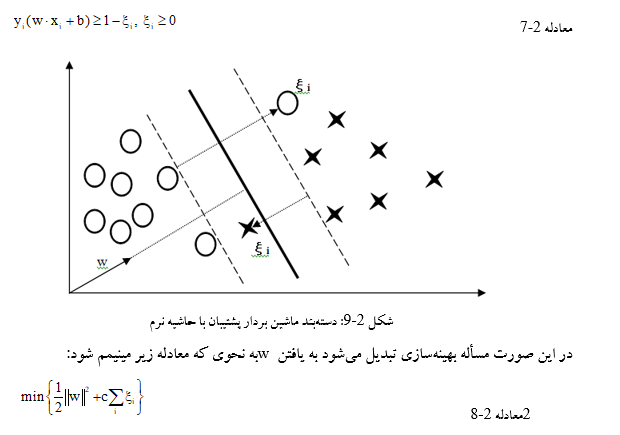
ماشین بردار پشتیبان با حاشیه نرم تلاش میکند ξi را صفر نگه دارد در حالی که حاشیههای دستهبند را حداکثر میکند. SVM تعداد نمونههایی که به اشتباه دستهبندی شدهاند را کمینه نمیکند بلکه سعی دارد مجموع فواصل از حاشیهی فراصفحهها را کمینه نماید . مقادیر بزرگ برای c سبب میشود که رابطه (2-6) مانند روش با حاشیه سخت عمل کند. ماشین بردار پشتیبان با حاشیه نرم همیشه یک راه حل پیدا میکند و در مقابل مجموعه دادههایی که دارای یک عضو جدا هستند مقاوم است و به خوبی عمل میکند.
ماشين بردار پشتيبان خطي
ماشين بردار پشتيبان يک روش يادگيري نسبتا جديد است که اغلب براي کلاسبندي باينري مورد استفاده واقع مي شود. فرض کنيد L مشاهده داريم که هر مشاهده مشتمل بر زوج هاي است که در آن . بردار ورودي و يک مقدار دو وضعيتي (1- يا 1+) است. ايده ي ماشين بردار پشتيبان مي کوشد، ابرصفحاتي در فضا رسم کند که عمل تمايز نمونه هاي کلاس هاي مختلف داده ها را بطور بهينه انجام دهد. مي توان يک ابرصفحه را از طريق رابطه زير نشان داد:
براي يک بردار خطي b با وزن w ، حاشيه جداسازي عبارتست از فاصله ي بين ابرصفحه تعريف شده توسط رابطه ي فوق و نزديکترين ويژگي به آن. هدف ماشين بردار پشتيبان يافتن ابرصفحه اي ست که بيشترين حاشيه ي جداسازي را داشته باشد. مهمترين وظيفه SVM ، يافتن پارامترهاي w0 و b0 بر اساس بردارهاي آموزشي داده شده، براي اين ابرصفحه بهينه است. براي يک بردار ويژگي X، فاصله تا ابرصفحه بهينه به صورت زير است:
از رابطه بالا نتيجه مي شود که ماکزيموم کردن حاشيه جداسازي بين الگوها و ابرصفحه، معادلست با مينيموم کردن فرم اقليدسي بردار وزن w. بنابراين مساله بهينه سازي مقيد را مي توان به صورت زير تعريف کرد:
براي حل اين مساله، تابع لاگرانژ زير را تشکيل داده و حل مي کنيم:
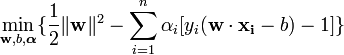
لاگرانژين L بايد نسبت به متغيرهاي اوليه bو w مينيموم و نسبت به متغيرهاي دوگان ماکزيموم شود. با مساوي صفر قراردادن مشتق L نسبت به b،w:
به معادلات زير خواهيم رسيد:
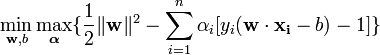
مجموعه جواب، بسطي از نمونه هاي آموزشي است که مقدار متناظر با آن ها، يک مقدار غير صفر است. اين نمونه هاي آموزشي خاص به بردارهاي پشتيبان مشهورند. بردارهاي پشتيبان روي مرز حاشيه قرار دارند. مابقي نمونه هاي آموزشي در اين قسمت نقشي ندارند.
ماشين بردار پشتيبان غيرخطي:
ابرصفحه جداکننده بهينه اولين بار توسط Vapnik در سال ۱۹۶۳ ارائه شد که يک دسته کننده خطي بود. در سال ۱۹۹۲ ،Bernhard Boser ، Isabelle GuyonوVapnik راهي را براي ايجاد دسته بند غيرخطي، با استفاده قرار دادن هسته براي پيدا کردن ابرصفحه با بيشتر حاشيه، پيشنهاد دادند. الگوريتم نتيجه شده ظاهرا مشابه است، به جز آنکه تمام ضرب هاي نقطه اي با يک تابع هسته غيرخطي جايگزين شده اند. اين اجازه مي دهد، الگوريتم، براي ابرصفحه با بيشترين حاشيه در يک فضاي ويژگيِ تغييرشکل داده، مناسب باشد. ممکن است، تغييرشکل غيرخطي باشد و فضاي تغيير يافته، داراي ابعاد بالاتري باشد. به هر حال دسته کننده، يک ابرصفحه در فضاي ويژگي با ابعاد بالا است، که ممکن است در فضاي ورودي نيز غيرخطي باشد.






