ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی درخت تصمیم یا Decision Tree

یکی از پرکاربردترین الگوریتمهای دادهکاوی، الگوریتم درخت تصمیم است. در دادهکاوی، درخت تصمیم یک مدل پیشبینی کننده است به طوری که میتواند برای هر دو مدل رگرسیون و طبقهای مورد استفاده قرار گیرد. زمانی که درخت برای کارهای طبقهبندی استفاده میشود، به عنوان درخت طبقهبندی (Classification Tree) شناخته میشود و هنگامی که برای فعالیتهای رگرسیونی به کار میرود درخت رگرسیون (Regression Decision Tree)نامیده میشود.
درختهای طبقهبندی برای طبقهبندی یک مجموعه رکورد به کار میرود. به صورت رایج در فعالیتهای بازاریابی، مهندسی و پزشکی استفاده میشود.
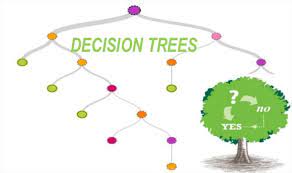
در ساختار درخت تصمیم، پیشبینی به دست آمده از درخت در قالب یک سری قواعد توضیح داده میشود. هر مسیر از ریشه تا یک برگ درخت تصمیم، یک قانون را بیان میکند و در نهایت برگ با کلاسی که بیشترین مقدار رکورد در آن تعلق گرفته برچسب میخورد.
اجزای اصلی درخت تصمیم
برگ (Leaf Nodes): گرههایی که تقسیمهای متوالی در آنجا پایان مییابد. برگها با یک کلاس مشخص میشوند.
ریشه (Root Node): منظور از ریشه، گره آغازین درخت است.
شاخه (Branches): در هر گره داخلی به تعداد جوابهای ممکن شاخه ایجاد میشود.

معیارهای انتخاب مشخصه برای انشعاب درخت تصمیم
یک معیار انتخاب مشخصه، یک ابتکار برای انتخاب معیار نقطه انشعاب است به طوری که بهترین تفکیک دادههای آموزش را به کلاسهای برچسبدار داشته باشد.
سه معیار انتخاب مشخصه شناخته شده عبارتند از:
- Information gain
- Gain ratio
- Gini index
الگوریتمهای شایع برای برقراری درخت تصمیم
ID3
یکی از الگوریتمهای بسیار ساده درخت تصمیم که در سال 1986 توسط Quinlan مطرح شده است. اطلاعات به دست آمده به عنوان معیار تفکیک به کار میرود. این الگوریتم هیچ فرایند هرس کردن را به کار نمیبرد و مقادیر اسمی و مفقوده را مورد توجه قرار نمیدهد.
C4.5
این الگوریتم درخت تصمیم، تکامل یافته ID3 است که در سال 1993 توسط Quinlan مطرح شده است.
Gain Ratio به عنوان معیار تفکیک در نظر گرفته میشود. عمل تفکیک زمانی که تمامی نمونهها پایین آستانه مشخصی واقع میشوند، متوقف میشود. پس از فاز رشد درخت عمل هرس کردن بر اساس خطا اعمال میشود. این الگوریتم مشخصههای اسمی را نیز در نظر میگیرد.
CART
برای برقراری درختهای رگرسیون و دستهبندی از این الگوریتم استفاده میشود. در سال 1984توسط Breiman و همکارانش ارائه شده است. نکته حائز اهمیت این است که این الگوریتم درختهای باینری ایجاد میکند به طوری که از هر گره داخلی دو لبه از آن خارج میشود و درختهای بدست آمده توسط روش اثربخشی هزینه، هرس میشوند.
یکی از ویژگیهای این الگوریتم، توانایی در تولید درختهای رگرسیون است. در این نوع از درختها برگها به جای کلاس مقدار واقعی را پیشبینی میکنند. الگوریتم برای تفکیک کنندهها، میزان مینیمم مربع خطا را جستجو میکند. در هر برگ، مقدار پیشبینی بر اساس میانگین خطای گرهها میباشد.
CHID
این الگوریتم درخت تصمیم به جهت در نظرگرفتن مشخصههای اسمی در سال 1981 توسط Kass طراحی شده است. الگوریتم برای هر مشخصه ورودی یک جفت مقدار که حداقل تفاوت را با مشخصه هدف داشته باشد، پیدا می کند.
مزایای درخت تصمیم
- درخت تصمیم بدیهی است و نیاز به توصیف ندارد.
- هر دو مشخصه اسمی و عددی را میتواند مورد توجه قرار دهد.
- نمایش درخت تصمیم به اندازه کافی برای نشان دادن هرگونه طبقهبندی غنی است.
- مجموعه دادههایی که ممکن است دارای خطا باشند را در نظر میگیرد.
- مجموعه دادههایی که دارای مقادیر مفقوده هستند را شامل میشود.
- درختهای تصمیم روشهای ناپارامتری را نیز مورد توجه قرار میدهد.