 ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی انتخاب ویژگی یا Feature Selection
برای مساله انتخاب ویژگی، راه حل ها و الگوریتم های فراوانی ارائه شده است که بعضی از آن ها قدمت سی یا چهل ساله دارند. مشکل بعضی از الگوریتم ها در زمانی که ارائه شده بودند، بار محاسباتی زیاد آن ها بود، اگر چه امروزه با ظهور کامپیوترهای سریع و منابع ذخیره سازی بزرگ، این مشکل به چشم نمی آید ولی از طرف دیگر، مجموعه های دادهای بسیار بزرگ برای مسائل جدید باعث شده است که همچنان پیدا کردن یک الگوریتم سریع برای این کار مهم باشد. مساله انتخاب ویژگی به وسیله نویسندگان مختلف، از دیدگاه های متفاوتی مورد بررسی قرار گرفته است. هر نویسنده نیز با توجه به نوع کاربرد، تعریفی را از آن ارائه داده است. در ادامه چند مورد از این تعاریف را بیان میکنیم:
1- تعریف ایده آل: پیدا کردن یک زیرمجموعه با حداقل اندازه ممکن، برای ویژگی ها است، که برای هدف موردنظر اطلاعات لازم و کافی را در بر داشته باشد. بدیهی است که هدف تمام الگوریتم ها و روشهای انتخاب ویژگی، همین زیر مجموعه است.
2- تعریف کلاسیک: انتخاب یک زیرمجموعه M عنصری از میان N ویژگی، به طوریکه M < N باشد و مقدار یک تابع معیار (Criterion Function) برای زیرمجموعه موردنظر، نسبت به سایر زیرمجموعه های هماندازه دیگر بهینه باشد. این تعریفی است که Fukunaga و Narenda در سال 1111 ارائه داده اند.
3- افزایش دقت پیشگوئی : هدف انتخاب ویژگی این است که یک زیرمجموعه از ویژگی ها برای افزایش دقت پیشگوئی، انتخاب شوند. به عبارت دیگر کاهش اندازه ساختار بدون کاهش قابل ملاحظه در دقت پیشگوئی طبقه بندی کنندهای که با استفاده از ویژگی های داده شده بدست می آید، صورت گیرد.
4- تخمین توزیع کلاس اصلی: هدف از انتخاب ویژگی این است که یک زیرمجموعه کوچک از ویژگی ها انتخاب شوند، توزیع ویژگی هایی که انتخاب میشوند، بایستی تا حد امکان به توزیع کلاس اصلی با توجه به تمام مقادیر ویژگی های انتخاب شده نزدیک باشد.
روش های مختلف انتخاب ویژگی، تلاش میکنند تا از میان زیر مجموعه کاندید، بهترین زیرمجموعه را پیدا کنند. در تمام این روش ها براساس کاربرد و نوع تعریف، زیر مجموعه ای به عنوان جواب انتخاب میشود، که بتواند مقدار یک تابع ارزیابی را بهینه کند. با وجود این که هر روشی سعی می کند که بتواند، بهترین ویژگی ها را انتخاب کند، اما با توجه به وسعت جواب های ممکن، و این که این مجموعه های جواب به صورت توانی با N افزایش پیدا می کنند، پیدا کردن جواب بهینه مشکل و در Nهای متوسط و بزرگ بسیار پر هزینه است. به طور کلی روش های مختلف انتخاب ویژگی را براساس نوع جستجو به دسته های مختلفی تقسیم بندی می کنند. در بعضی روشها تمام فضای ممکن جستجو میگردد. در سایر روشها که میتواند مکاشفه ای و یا جستجوی تصادفی باشد، در ازای از دست دادن مقداری از کارایی، فضای جستجو کوچکتر میشود.
روش های مختلف انتخاب ویژگی
تکنیک های انتخاب ویژگی را می توان به دو شیوه دسته بندی کرد : در یک شیوه، روش های مختلف انتخاب ویژگی را براساس دو معیار تابع تولید کننده و تابع ارزیابی طبقه بندی میکنیم و براساس رویکرد دیگر تکنیک های انتخاب ویژگی را به سه دسته Filter ، Wrapper و embedded or hybrid تقسیم می کنیم.
روش فیلتر Filter برای انتخاب ویژگی:
ویژگی ها را براساس یک مرحله پیش پردازش که الگوریتم یادگیری را نادیده می گیرد انتخاب میکند. روش فیلتر براساس
ویژگی های ذاتی داده بنا شده است نه براساس دسته بند خاصی. ذات فیلترها برجستجوی ویژگی های وابسته و حذف غیر وابسته ها است. الگوریتم های فیلتر بر پایه چهار معیار ارزیابی مختلف به نام های “مسافت ،اطلاعات ،وابستگی و سازگاری” ارزیابی می شوند .به راحتی برای دیتاست های با ابعاد بالا به کار می روند. از نظر محاسباتی خیلی ساده و سریع هستند و مستقل از الگوریتم دسته بندی هستند . شیوه کار آنها به این طریق است که ابتدا ویژگی ها را به وسیله یک سری معیارها امتیازدهی می کند. سپس d تا از بهترین ویژگی ها را انتخاب می کند. سپس این مجموعه به عنوان ورودی به الگوریتم دسته بندی، داده می شود. به بیان دیگر به طور مستقل به تک تک ویژگی ها امتیازی داده می شود و سپس براساس آن امتیازات مرتب می شوند. این امتیازات می توانند نشان دهنده رابطه بین ویژگی و عنوان کلاس باشند. بدین منظور می توان از تست t یا تست فیشر استفاده کرد. مشکل رویکرد فیلتر آن است که رابطه درونی بین ویژگی ها درنظر گرفته نشده و ممکن است مجموعه انتخابی دارای تعداد زیادی ویژگی وابسته به هم باشد، درنتیجه هدف ما که کاهش ویژگی تا حد ممکن و حذف ویژگی های غیرضروری است را محقق نمی سازد.
انتخاب ویژگی به روش Wrapper:
این رویکرد مجموعه ویژگی را براساس دسته بندی کننده، انتخاب می کند و این مجموعه را با استفاده از دقت پیش بینی یا میزان خوب بودن خوشه ها امتیازدهی می کند یعنی کلاس بندی را یک جعبه سیاه محسوب می کند و زیر مجموعه ویژگی ها را براساس توان پیش بینی آن ها رتبه بندی می کند. این متد از بعضی استراتژی های جستجو مثل SFS و SBS استفاده می کند. این روش ها به روش های ترتیبی منسوب هستند. در این رویکرد، تمامی زیرمجموعه های ممکن از ویژگی ها درنظر گرفته می شود و با ارزیابی همه حالت ها بهترین آن ها که کمترین خطای عمومی را به همراه دارد انتخاب می شود. این متدها در انواع مسائل قادر به یافتن بهترین پاسخ می باشند. اگرچه ممکن است روش های wrapper نسبت به روش های فیلتر نتایج بهتری را تولید کنند ولی اجرای این روش ها پرهزینه است و در بعضی مواقع که تعداد ویژگی ها زیاد باشد منجر به شکست می شوند. مشکل اصلی روش های بسته بندی پیچیدگی بسیار بالاست که منجر به کنترل ناپذیرشدن مسیر حل مسئله می شود.
روش Embedded برای انتخاب ویژگی:
این مدل از مزایای هر دو مدل قبلی به وسیله استفاده از معیارهای ارزیابی مختلفشان در مراحل متفاوت جستجو سود می برد. در متد embedded جستجو برای یک مجموعه ویژگی بهینه ، درون ساختار دسته بندی کننده قرار دارد. در این رویکرد کنترل انتخاب تعداد مناسب ویژگی مشکل است و معمولا با افزونگی ویژگی ها مواجه می شویم. در اینجا نیز ارتباط بین ویژگی ها نادیده گرفته شده است که باعث مشکلاتی در انتخاب نهایی ویژگی ها می شود.
الگوریتم ژنتیک-genetic :
الگوريتم هاي ژنتيك از اصول انتخاب طبيعي داروين براي يافتن فرمول بهينه جهت پيش بيني يا تطبيق الگو استفاده ميكنند. الگوريتم هاي ژنتيك اغلب گزينه خوبي براي تكنيك هاي پيش بيني بر مبناي رگرسيون هستند.جذابيت زياد الگوريتم هاي ژنتيك اين است نتايج نهايي قابل ملاحظه تري دارند. فرمول نهايي براي كاربر قابل مشاهده خواهد بود و براي ارايه سطح اطمينان نتايج ميتوان تكنيك هاي آماري متعارف را بر روي اين فرمولها اعمال كرد. به اختصار گفته مي شود كه الگوريتم ژنتيك يك فن برنامه نويسي است كه از تكامل ژنتيكي به عنوان يك الگوي حل مساله استفاده ميكند. الگوريتم ژنتيك يك فن جستجو در علوم مهندسي براي يافتن راه حل بهينه ومسايل جستجو است.الگوريتم هاي ژنتيك يكي از انواع الگوريتم هاي تكاملي هستند؛ كه از علم زيست شناسي مثل وراثت ، جهش ، انتخاب ناگهاني، انتخاب طبيعي و تركيب الهام گرفته شده است.به طور معمول راهحلها به صورت اعداد دودويي نشان داده ميشوند، ولي روش هاي نمايش ديگري هم وجود دارد كه در ادامه اين فصل معرفي خواهند شد. تكامل از يك مجموعه به طور كامل تصادفي از موجوديت ها شروع مي شود و در نسل هاي بعدي تكرار ميشود و در هر نسل ، مناسب ترين ها انتخاب ميشوند نه بهترينها. راهحلهاي هر مساله به وسيله يك ليست از پارامترها نشان داده ميشود كه به
آنها كروموزوم 3 يا ژنوم گفته ميشود. كروموزوم ها به طور معمول به صورت يك رشته ساده از داده ها نمايش داده مي شوند، البته انواع ساختمان داده هاي ديگر هم مي توانند مورد ا ستفاده قرار بگيرند . الگوريتم هاي ژنتيك پس از طي چندين مرحله از توليد نسل در نهايت بايد بر اساس يك سري شرايط خاصي به اجراي خود خاتمه دهند.
اصول ابتدایی در الگوریتم ژنتیک
اصول کاری الگوریتم ژنتیک، در ساختار الگوریتمی زیر نمایش داده شده است. مهمترین گام لازم برای پیادهسازی الگوریتم ژنتیک و انواع مختلف آن عبارتند از: تولید جمعیت (اولیه) از جوابهای یک مسأله، مشخص کردن تابع هدف، تابع «برازندگی» (Fitness) و به کار گرفتن «عملگرهای ژنتیک» (Genetic Operators) جهت ایجاد تغییرات در جمعیت جوابهای مسأله. عملگرهای ژنتیک قابل تعریف در الگوریتم ژنتیک، در ادامه معرفی خواهند شد. اصول کاری الگوریتم ژنتیک عبارتست از:
- فرموله کردن جمعیت ابتدایی متشکل از جوابهای مسأله
- مقداردهی اولیه و تصادفی جمعیت ابتدایی متشکل از جوابهای مسأله
- حلقه تکرار:
- ارزیابی تابع هدف مسأله
- پیدا کردن تابع برازندگی مناسب
- انجام عملیات روی جمعیت متشکل از جوابهای مسأله با استفاده از عملگرهای ژنتیک
- عملگر «تولید مثل» (Reproduction)
- عملگر «ترکیب یا آمیزش» (Crossover)
- عملگر «جهش» (Mutation)
- تا زمانی که: شرط توقف ارضا شود.
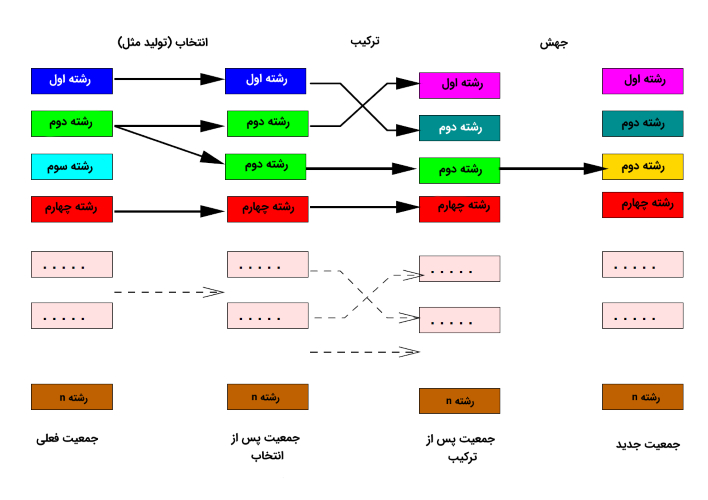
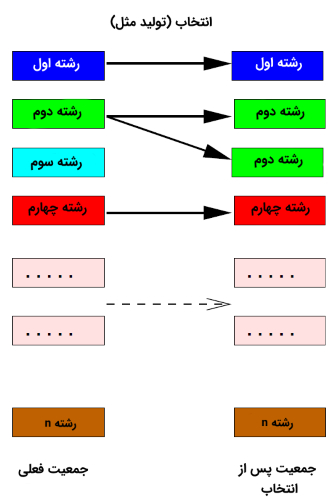
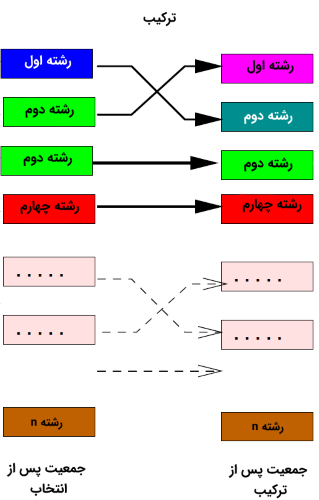
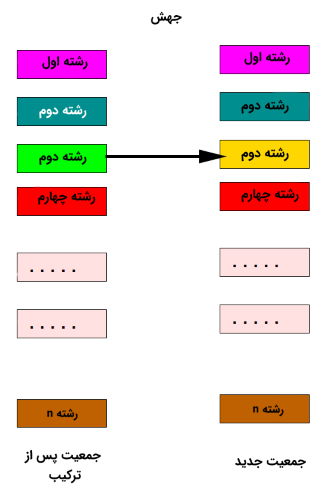
نمای کلی از سومین مرحله از فرایند تکاملی در الگوریتم ژنتیک پس از جهش (ادامه تصویر قبلی)
یکی از مهمترین ویژگیهای الگوریتم ژنتیک، کدبندی متغیرهای لازم برای توصیف مسأله است. مرسومترین روش کدبندی متغیرهای مسأله، تبدیل متغیرها به رشته یا برداری از مقادیر باینری، صحیح و یا حقیقی است. بهترین عملکرد الگوریتمهای ژنتیک معمولا زمانی اتفاق میافتد که از نمایش باینری برای کدبندی متغیرهای مسأله استفاده میشود.
اگر مسألهای که قرار است جوابهای بهینه آن مشخص شود بیش از یک متغیر داشته باشد، به تعداد متغیرهای آن مسأله، «کدبندیهای تک متغیره» (Single-Variable Coding) متناظر با تک تک آنها ایجاد و با یکدیگر ادغام میشوند. در چنین حالتی، یک «کدبندی چند متغیره» (Multi-Variable Coding) از مسأله مورد نظر شکل خواهد گرفت. یکی از مهمترین ویژگیهای الگوریتمهای ژنتیک، پردازش همزمان چندین جواب کاندید تولید شده برای مسأله تعریف شده است.
بنابراین، در مرحله اول از پیادهسازی الگوریتم ژنتیک، مجموعهای متشکل از P موجودیت یا کروموزوم توسط «مولدهای شبه تصادفی» (Pseudo Random Generators) تشکیل میشود. هر کدام از موجودیتها با کروموزومهای موجود در این جمعیت، یک جواب کاندید و امکانپذیر برای مسأله را نمایش میدهند. هر کدام از این موجودیتها، یک نمایش برداری از جواب مسأله در یک «فضای جواب» (Solution Space) هستند که به آنها «جواب اولیه» (Initial Solution) نیز گفته میشود.
از آنجایی که عملیات جستجو از مجموعهای از جوابها (جوابهای اولیه به طور تصادفی در فضای جواب پراکنده شدهاند) در فضای جواب مسأله آغاز میشود، جستجوی قدرتمند و بدون بایاس در الگوریتم ژنتیک تضمین خواهد شد. در مرحله بعد، تمامی جوابهای اولیه تولید شده مورد ارزیابی قرار میگیرند تا مقدار تابع هدف هر کدام از آنها مشخص شود.
در این مرحله، معمولا یک «تابع جریمه خارجی» (Exterior Penalty Function) به کار گرفته میشود تا «مسأله بهینهسازی مقید» (Constrained Optimization Problem) به یک مسأله بهینهسازی «نامقید» (Unconstrained) تبدیل شود. چنین تبدیلی، بسته به مسائل بهینهسازی مختلف (مسائلی که قرار است جوابهای بهینه آنها تولید شود)، متفاوت خواهد بود.
در مرحله سوم، تابع هدف مسأله به یک تابع برازندگی نگاشت میشود. از طریق تابع برازندگی، «مقدار برازندگی» (Fitness Value) هر یک از اعضای جمعیت اولیه مشخص میشود. پس از مشخص شدن مقدار برازندگی جوابهای کاندید، از عملگرهای الگوریتم ژنتیک جهت انجام تغییرات روی جوابهای کاندید استفاده میشود.
اصول کاری الگوریتم ژنتیک
برای نمایش اصول کاری الگوریتم ژنتیک، یک مسأله بهینهسازی نامقید در نظر گرفته میشود. فرض کنید که مسأله بهینهسازی زیر داده شده است و هدف الگوریتم ژنتیک، «بیشینهسازی» (Maximizing) تابع زیر باشد:
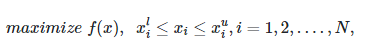
در این رابطه، xlixil و xuixiu حد بالا و حد پایین تعیین شده برای مقادیر متغیر xixi است. اگر چه در اینجا از یک مسأله بیشینهسازی برای نمایش اصول کاری الگوریتم ژنتیک استفاده است، با این حال، الگوریتم ژنتیک به راحتی قادر به کمینهسازی مسائل مختلف نیز خواهد بود. برای پیادهسازی الگوریتمهای ژنتیک، وظایف خاصی باید تعریف و توسط این الگوریتم، جهت بهینهسازی توابع مختلف، اجرا شوند.






