ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی دیتاست SECOM
در حال بارگذاری
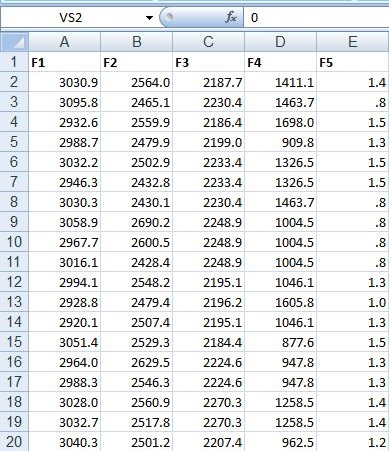
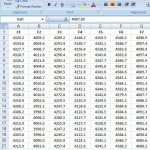
این پروژه مربوط به دیتاست SECOM می باشد .فرآیند تولید نیمه هادی پیچیده مدرن به طور معمول تحت نظارت شدید از طریق نظارت بر سیگنال ها متغیرهای جمع آوری شده از سنسورها و یا نقاط اندازه گیری فرایند انجام می شود. با این حال، همه این سیگنال ها در یک سیستم نظارت خاص به همان اندازه ارزشمند نیستند. سیگنال های اندازه گیری شامل ترکیبی از اطلاعات مفید، اطلاعات نامناسب و همچنین نویز است. اغلب موارد این است که اطلاعات مفید در دو دز دفن شده اند. مهندسان معمولا سیگنال های بسیار بیشتری از آنچه در واقع مورد نیاز هستند، دارند. اگر هر نوع سیگنال را به عنوان یک ویژگی در نظر بگیریم، انتخاب ویژگی ممکن است برای شناسایی سیگنال های مربوطه مورد استفاده قرار گیرد. مهندسین فرآیند ممکن است از این سیگنال ها برای تعیین عوامل کلیدی که موجب انجام سفرهای گوناگون در پایین روند در فرآیند می شوند استفاده کنند. این باعث افزایش کارایی فرآیند، کاهش زمان یادگیری و کاهش هزینه های واحد تولید می شود.برای ارتقاء تکنیک های بهبود کسب و کار در حال حاضر، استفاده از انتخاب ویژگی به عنوان یک روش سیستم هوشمند مورد بررسی قرار گرفته است.داده های ارائه شده در این مورد نشان دهنده یک انتخاب از چنین ویژگی هایی است که هر نمونه یک واحد تولید واحد با ویژگی های اندازه گیری مربوطه را نشان می دهد و برچسب ها نشان دهنده یک عملکرد عبور شکست ساده برای آزمایش خط داخلی، شکل ۲ و تاریخ زمان مربوط به زمان است. مربوط به عبور و مربوط به یک شکست است و مهر تایمر داده ها برای آن نقطه آزمون خاص است.با استفاده از تکنیک های انتخاب ویژگی دلخواه است که ویژگی ها را با توجه به تاثیر آنها بر عملکرد کلی محصول، رتبه بندی کنید، روابط نیز ممکن است با توجه به شناسایی ویژگی های کلیدی در نظر گرفته شود.نتایج به دست آمده از لحاظ ویژگی مرتبط بودن برای پیش بینی پذیری با استفاده از خطاهای به عنوان معیار ارزیابی ما ارائه می شود. پیشنهاد می شود که اعتبارسنجی متقابل برای تولید این نتایج اعمال شود. برخی از نتایج پایه در زیر برای تکنیک های انتخاب اساسی با استفاده از یک طبقه بندی ساده رشته کرنل و اعتبار سنجی متقابل ۱۰ برابر نشان داده شده است.
نتایج پایه: اشیاء قبل از پردازش به مجموعه داده ها به سادگی برای استاندارد سازی داده ها و حذف ویژگی های ثابت استفاده شد و سپس تعدادی از اشیاء انتخاب ویژگی های مختلف که ۴۰ بالاترین ویژگی رتبه بندی شده را با یک طبقه بندی ساده برای رسیدن به نتایج اولیه به کار برده بودند. اعتبار سنجی متقارن ۱۰ برابر و میزان خطای متعادل (* BER) به عنوان ماتریس عملکرد اولیه ما برای کمک به بررسی این مجموعه داده تولید شد.
تعداد نمونه ها:
۱۵۶۷
تعداد ویژگی ها:
۵۹۱
داده های پرت:
این دیتاست فاقد داده های پرت یا Missing Values می باشد
- این دیتاست دارای یک داکیومنت کامل فارسی است. در این داکیومنت عنوان دیتاست، توضیحات کامل دیتاست، تعداد ویژگی ها، تعداد نمونه ها، توضیح تمام ویژگی های موجود و لینک دیتاست تشریح شده است.
- این دیتاست دارای یک داکیومنت کامل انگلیسی نیز می باشد، که در این دیتاست اطلاعات کاملی به زبان لاتین در رابطه با دیتاست معرفی شده ارائه شده است.
- پس از خرید، امکان دانلود فایل اصلی دیتاست در قالب فایل اکسل میسر است.
- فایل پیش پردازش دیتاست
- وجود فایل ARFF و قابل اجرا در نرم افزار داده کاوی مثل وکا
- امکان دانلود لینک دیتاست در یک فایل متنی به صورت جداگانه
نکته: برای این دیتاست انواع الگوریتم های داده کاوی اعم از ۱۴۷ الگوریتم دسته بندی (مثل: درخت تصمیم، شبکه عصبی، ماشین بردار پشتیبان و …)، ۶ الگوریتم خوشه بندی (مثل: K-Means ، DBSCAN ،X-Means و…)، ۳ الگوریتم انجمنی (مثل Apriori ، FP-Growth و …) و چندین الگوریتم انتخاب ویژگی (مثل PSO و …) با استفاده از ابزارهای داده کاوی و برنامه نویسی اعم از رپیدماینر، وکا، تاناگرا، SPSS، مدلر، کلمنتاین، متلب و … تهیه و پیاده سازی شده است.
- لینک دانلود فایل بلافاصله پس از پرداخت وجه نمایش داده می شود.
- همچنین لینک دانلود به ایمیل شما ارسال خواهد شد به همین دلیل ایمیل خود را به دقت وارد نمایید.
- ممکن است ایمیل ارسالی به پوشه اسپم یا Bulk ایمیل شما ارسال شده باشد.
- در صورتی که به هر دلیلی موفق به دانلود فایل مورد نظر نشدید کافیست به ایمیل سایت درخواستتان را ارسال نمایید.
- حدود 90% از پروژه ها دارای داکیومنت و فیلم آموزشی می باشند.