ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی خوشهبندی (Clustering)
«تحلیل خوشهبندی» (Cluster Analysis) یا بطور خلاصه خوشهبندی، فرآیندی است که به کمک آن میتوان مجموعهای از اشیاء را به گروههای مجزا افراز کرد. هر افراز یک خوشه نامیده میشود. اعضاء هر خوشه با توجه به ویژگیهایی که دارند به یکدیگر بسیار شبیه هستند و در عوض میزان شباهت بین خوشهها کمترین مقدار است. در چنین حالتی هدف از خوشهبندی، نسبت دادن برچسبهایی به اشیاء است که نشان دهنده عضویت هر شیء به خوشه است.
به این ترتیب تفاوت اصلی که بین تحلیل خوشهبندی و «تحلیل طبقهبندی» (Classification Analysis) وجود دارد، نداشتن برچسبهای اولیه برای مشاهدات است. در نتیجه براساس ویژگیهای مشترک و روشهای اندازهگیری فاصله یا شباهت بین اشیاء، باید برچسبهایی بطور خودکار نسبت داده شوند. در حالیکه در طبقهبندی برچسبهای اولیه موجود است و باید با استفاده از الگویهای پیشبینی قادر به برچسب گذاری برای مشاهدات جدید باشیم.
خوشهبندی سلسله مراتبی (Hierarchical Clustering)
یکی از روشهای «یادگیری ماشین» (Machine Learning) که به «آموزش بدون نظارت» (Unsupervised Learning) شهرت دارد، تحلیل خوشهبندی (Clustering Analysis) است. در این روش، برعکس خوشه بندی k-میانگین، هر مشاهده ممکن است در بیش از یک خوشه قرار گیرد زیرا براساس سطوح مختلف فاصله، خوشهها تشکیل میشود. بنابراین هر خوشه ممکن است زیر مجموعه خوشه دیگر در سطحی از فاصله قرار گیرد. به هر حال خوشهبندی روش است که به کمک «ویژگیها» (Features) یا «صفتها» (Attributes) مشاهدات، آن را به گروههای مشابه طبقهبندی میکند.
انتخاب ویژگیهای مناسب برای این کار، یکی از مسائل مهمی است که باید در نظر گرفته شود. از طرف دیگر استانداردسازی دادهها نیز مطرح است تا مقیاس اندازهگیری صفت یا ویژگیها باعث انحراف تابع فاصله نشود. با توجه به بار محاسباتی زیادی که روشهای خوشهبندی دارند، استفاده و یا ایجاد تکنیکهایی که در زمان کوتاهتر بتوانند با دقت مناسب پاسخهای خوشهبندی را تولید کنند نیز از موضوعات تحقیقاتی به روز در زمینه یادگیری ماشین بخصوص در فضای کلان دادهها است.
نمودار زیر نتیجه یک خوشهبندی سلسله مراتبی را به صورت «درختواره نگار» (Dendrogram) نشان میدهد.
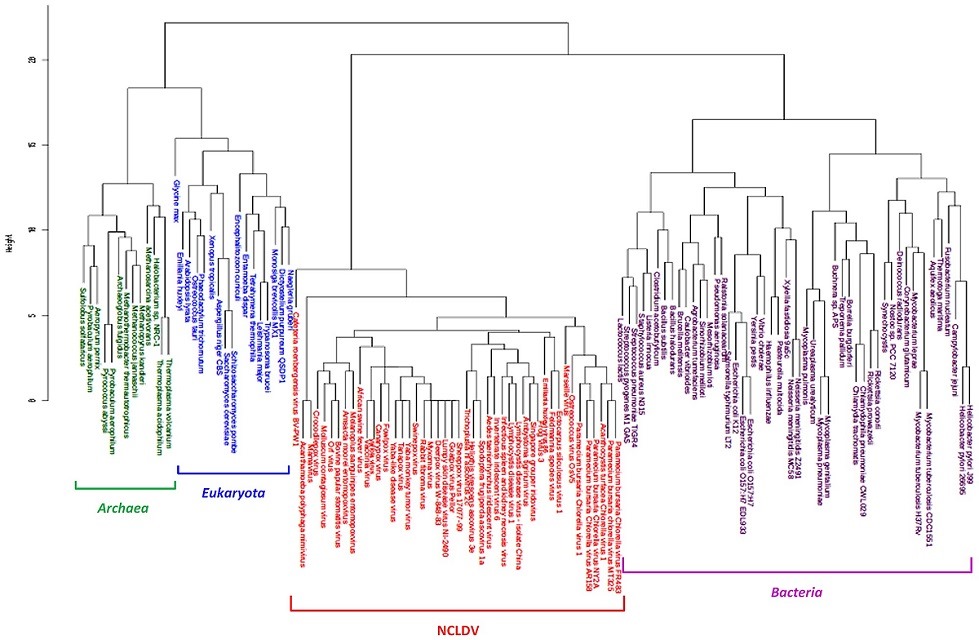
خوشهبندی سلسله مراتبی با روش تجمیعی: اگر دیدگاه به این نمودار از پایین به بالا باشد (Bottom-Up)، برحسب ارتفاع نمودار (Height) در سطح پایینی، خوشهها زیرمجموعه خوشههای سطح بالاتر هستند در نتیجه به نظر میرسد که خوشههای زیرین با یکدیگر ترکیب شده و خوشههای سطح بالاتر را ایجاد میکنند. این شیوه خوشه بندی سلسله مراتبی به روش «تجمیعی» (Agglomerative) معروف است. برای نامگذاری این روش معمولا از عبارت اختصاری HAC که خلاصه Hierarchical Agglomertive Clustering است، استفاده میشود.
خوشهبندی سلسله مراتبی با روش تقسیمی: برعکس اگر دیدگاه از بالا به پایین (Top-Down) باشد، خوشههای بالایی به زیرخوشهها دیگر تجزیه میشوند تا آنکه به خوشههایی با تنها یک عضو برسیم. به این ترتیب بزرگترین خوشه که شامل همه مشاهدات است به کوچکترین خوشهها که شامل تنها یک مشاهده است تقسیم میشود. به این روش »تقسیمی» (Divisive) گفته میشود. از آنجایی که این روش دارای محدودیتهایی است کمتر در خوشهبندی سلسله مراتبی به کار گرفته میشود. بنابراین در این نوشتار به معرفی روش تجمیعی پرداخته ولی با دستوراتی در R که خوشهبندی تقسیمی را انجام میدهند آشنا میشویم.
پیچیدگی زمانی الگوریتم خوشهبندی سلسله مراتبی تجمیعی
در الگوریتم HAC پیچیدگی زمانی برابر با O(n3) و فضای مورد نیاز حافظه نیز برابر با O(n2) است. بنابراین با افزایش حجم دادهها، سرعت و فضای حافظه برای اجرای عملیات خوشهبندی به شدت افزایش مییابد. به همین دلیل معمولا از این الگوریتم برای خوشهبندی «کلان داده» (Big Data) استفاده نمیشود.
مراحل خوشهبندی سلسله تجمیعی
برای اجرای محاسبات مربوط به این روش خوشهبندی، به دو معیار فاصله (شباهت) احتیاج داریم. ۱- میزان فاصله بین زوج مشاهدات. ۲- میزان فاصله بین خوشهها. در حالت اول توابع فاصله برای دادههای کمی یا کیفی قابل استفاده هستند. بنابراین اگر دادهها کمی باشند برای مثال میتوان از فاصله اقلیدسی یا فاصله منهتن استفاده کرد. همچنین برای دادههای کیفی نیز میتوان از میزان انطباق ساده (Simple Matching) و یا «فاصله همینگ» (Hamming Distance) برای داده های کمک گرفت.
معمولا قبل از شروع مراحل خوشهبندی سلسله مراتبی تجمیعی، از یک «ماتریس فاصله» (Distance Matrix) یا «ماتریس شباهت» (Similarity Matrix) برای تسریع در محاسبات کمک گرفته میشود. این ماتریس نشان میدهد که فاصله بین هر زوج از مشاهدات چقدر است. البته نوع تابعی که باید بوسیله آن فاصله اندازهگیری شود، در مقدارهای موجود در این ماتریس تاثیر گذار است.
در خوشهبندی سلسله مراتبی تجمیعی یا HAC، با توجه به مقدارهای این ماتریس، مشاهدات یا خوشههایی که دارای کمترین فاصله (بیشترین شباهت) هستند با هم ادغام میشوند و خوشه جدیدی میسازند. در مرحله بعد باز هم فاصله بین مشاهدات و یا خوشههای جدید، توسط ماتریس فاصله که به روز رسانی شده، محاسبه و کار ادغام ادامه پیدا میکند تا تنها یک خوشه باقی بماند.