ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی پروژه خوشه بندی داده های دیابت با استفاده از الگوریتم k-means در وکا (weka)
در حال بارگذاری
پروژه خوشه بندی داده های دیابت با استفاده از الگوریتمk-means در وکا (weka)
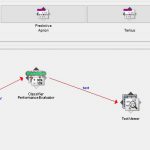
این پروژه داده های مربوط به داده های دیابت را با استفاده از الگوریتم خوشه بندی K-MEANS در نرم افزار داده کاوی وکا (weka) خوشه بندی میکند. همان طور که می دانید الگوریتم خوشه بندی K-MEANS تعدادی خوشه را به عنوآن ورودی دریافت نموده و بر اساس تعداد خوشه های وارد شده(k) توسط کاربر، اقدام به خوشه بندی داده ها نموده و خروجی هایی را نمایش میدهد. عملیات خوشه بندی با استفاده از الگوریتم k-means انجام می گردد. روش کار بدین صورت است که ابتدا داده های مربوط به داده های دیابت را به نرم افزار داده کاوی وکا وارد نموده، سپس داده ها را جهت افزایش دقت خوشه بندی نرمال سازی می کنیم. پس از نرمال سازی داده ها الگوریتم k-means بروی داده های نرمال شده اعمال می گردد و خروجی را در قالب یک فایل اکسل با اضافه نمودن برچسپ خوشه (Cluster) تولید می کند.
الگوریتم استفاده شده جهت خوشه بندی داده های دیابت k-means است. معیار خوشه بندی بر اساس اطلاعات دموگرافیک داده های دیابت بوده و از فاصله اقلیدوسی جهت خوشه بندی داده های دیابت استفاده می شود. در این پروژه تعداد خوشه ها را می توان به صورت پویا تعیین نموده و نتایج را مورد بررسی قرار داد.
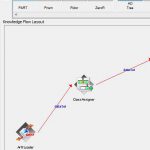
جهت خوشه بندی داده های دیابت میبایست ابتدا داده های مربوطه را به فرم پذیرفته شده نرم افزار داده کاوی وکا تبدیل نمود. بدین منظور کافیست داده های اکسل یا داده های متنی تبدیل به یک فایل با پسوند CSV شوند. مراحل انجام خوشه بندی داده های دیابت به صورت ذیل ارائه می گردد:
- ابتدا داده های مربوط به داده های دیابت را تبدیل به فرمت قابل قبول وکا(یک فایل با پسوند CSV) می کنیم.
- سپس با استفاده از نرم افزار داده کاوی وکا و از طریق منوی preprocess، داده ها را به برنامه ایمپورت نموده و ادامه مراحل را انجام خواهیم داد.
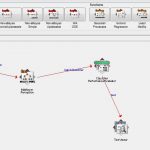
- پس از وارد نمودن دیتاست داده های دیابت به نرم افزار، میبایست جهت انسجام داده ها یک فیلتر Normalize بروی دیتاست اعمال شود. بدین منظور از پنل Filter گزینه choose را انتخاب کرده و از منوی باز شده گزینه های weka à Filter è unsupervised è Normalize را انتخاب نموده و در نهایت بروی دکمه Apply کلیک میکنیم تا فیلتر مورد نظر به صورت زیر اعمال شود.
- به کلیه مراحل انجام شده بالا، پیش پردازش بروی داده ها گفته میشود. بعد از انجام مراحل فوق از منوی Cluster عملیات خوشه بندی را انجام می دهیم.
- لازم به ذکر است که جهت خوشه بندی داده ها و انتخاب ورودی های مسئله راه های مختلفی وجود دارد که در پژوهش فعلی انتخاب نمونه ها به صورت ۷۰% داده های آموزشی و ۳۰% داده های آزمایشی انتخاب شده است. در این مرحله کافیست از Cluster الگوریتم k-means را انتخاب نموده و با کلیک بروی نام آن به مراتب k های مختلف را مورد ارزیابی قرار دهیم.
- در نهایت به ازای کلیه k های تنظیم شده برای الگوریتم k-means میزان خطا را محاسبه و نسبت به سایر مقادیر، ارزیابی می کنیم.
بنابراین با انجام مراحل فوق می توان بر روی داده های مربوط به داده های دیابت فرآیند خوشه بندی را انجام داده و نتایج مورد نظر را استخراج نمود.
امکانات پروژه خوشه بندی داده های دیابت
برخی از مهمترین امکانات این پروژه عبارتند از:
۱)تحویل یک فیلم ویدیویی از نحوه شبه سازی و خروجی وکا
۲)تحویل داکیومنت در قالب فایل word
۳) تحویل دیتاست استفاده شده
توجه:
جهت سفارش پروژه دیگر با سایر الگوریتم ها و سایر ابزار های داده کاوی مثل Weka, SPSS Modeler, Matlab,… بر روی سایر دیتاست ها کافیست با پشتیبانی سایت از طریق راه های ارتباطی(ایمیل، تلگرام، واتساپ) تماس حاصل نموده و سفارش خود را ثبت نمایید.
- لینک دانلود فایل بلافاصله پس از پرداخت وجه نمایش داده می شود.
- همچنین لینک دانلود به ایمیل شما ارسال خواهد شد به همین دلیل ایمیل خود را به دقت وارد نمایید.
- ممکن است ایمیل ارسالی به پوشه اسپم یا Bulk ایمیل شما ارسال شده باشد.
- در صورتی که به هر دلیلی موفق به دانلود فایل مورد نظر نشدید کافیست به ایمیل سایت درخواستتان را ارسال نمایید.
- حدود 90% از پروژه ها دارای داکیومنت و فیلم آموزشی می باشند.