 ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی الگوریتم جنگل تصادفی چیست ؟
جنگل تصادفی (Random forest) یک الگوریتم یادگیری تحت نظارت است که از آن هم برای طبقه بندی و هم رگرسیون استفاده می شود.
اما به طور کلی برای مسائل طبقه بندی از آن استفاده می شود. همانطور که میدانیم یک جنگل از درختان ساخته شده است و درختان بیشتر به معنای جنگل مقاوم تر است. به طور مشابه، الگوریتم درخت تصادفی روی نمونه های داده، درختان تصمیم گیری می سازد و سپس از هر کدام از آنها پیش بینی می گیرد و در نهایت به واسطه رای گیری، بهترین راه حل را انتخاب می کند. این یک روش گروهی است که از یک درخت تصمیم گیری مجزا بهتر است، زیرا با میانگین گیری در نتیجه، over-fitting را کاهش می دهد.
عملکرد الگوریتم جنگل تصادفی:
- ابتدا، از مجموعه داده فراهم شده نمونه های تصادفی را انتخاب کنید.
- سپس،این الگوریتم برای هر نمونه، یک درخت تصمیم گیری خواهد ساخت و در ادامه از هر درخت تصمیم گیری، نتیجه پیش بینی را خواهد گرفت.
- در این مرحله، برای هر نتیجه پیش بینی، رای گیری انجام می شود.
- در انتها، آن نتیجه پیش بینی که بیشترین تعداد رای را داشته باشد به عنوان نتیجه پیش بینی نهایی انتخاب می شود.
چگونگی عملکرد جنگل تصادفی
جنگل تصادفی یک الگوریتم یادگیری نظارت شده محسوب میشود. همانطور که از نام آن مشهود است، این الگوریتم جنگلی را به طور تصادفی میسازد. «جنگل» ساخته شده، در واقع گروهی از «درختهای تصمیم» (Decision Trees) است. کار ساخت جنگل با استفاده از درختها اغلب اوقات به روش «کیسهگذاری» (Bagging) انجام میشود. ایده اصلی روش کیسهگذاری آن است که ترکیبی از مدلهای یادگیری، نتایج کلی مدل را افزایش میدهد. به بیان ساده، جنگل تصادفی چندین درخت تصمیم ساخته و آنها را با یکدیگر ادغام میکند تا پیشبینیهای صحیحتر و پایدارتری حاصل شوند.
یکی از مزایای جنگل تصادفی قابل استفاده بودن آن، هم برای مسائل دستهبندی و هم رگرسیون است که غالب سیستمهای یادگیری ماشین کنونی را تشکیل میدهند. در این مطلب، عملکرد جنگل تصادفی برای انجام «دستهبندی» (Classification) تشریح خواهد شد، زیرا گاهی دستهبندی را به عنوان بلوک سازنده یادگیری ماشین در نظر میگیرند. در تصویر زیر، میتوان دو جنگل تصادفی ساخته شده از دو درخت را مشاهده کرد.
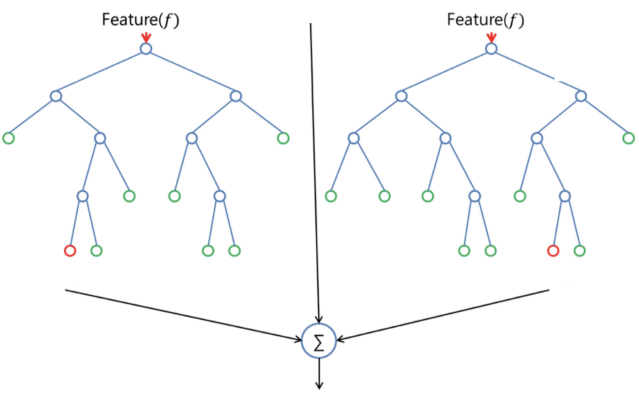
جنگل تصادفی دارای فراپارامترهایی مشابه درخت تصمیم یا «دستهبند کیسهگذاری» (Bagging Classifier) است. خوشبختانه، نیازی به ترکیب یک درخت تصمیم با یک دستهبند کیسهگذاری نیست و میتوان از «کلاس دستهبندی» (Classifier-Class) جنگل تصادفی استفاده کرد. چنانکه پیشتر بیان شد، با جنگل تصادفی، و در واقع «رگرسور جنگل تصادفی» (Random Forest Regressor) میتوان به حل مسائل رگرسیون نیز پرداخت.
جنگل تصادفی، تصادفی بودن افزودهای را ضمن رشد درختان به مدل اضافه میکند. این الگوریتم، به جای جستوجو به دنبال مهمترین ویژگیها هنگام تقسیم کردن یک «گره» (Node)، به دنبال بهترین ویژگیها در میان مجموعه تصادفی از ویژگیها میگردد. این امر منجر به تنوع زیاد و در نهایت مدل بهتر میشود. بنابراین، در جنگل تصادفی، تنها یک زیر مجموعه از ویژگیها توسط الگوریتم برای تقسیم یک گره در نظر گرفته میشود. با استفاده افزوده از آستانه تصادفی برای هر ویژگی به جای جستوجو برای بهترین آستانه ممکن، حتی میتوان درختها را تصادفیتر نیز کرد (مانند کاری که درخت تصمیم نرمال انجام میدهد).
مزایا و معایب

همانطور که پیش از این بیان شد، یکی از مزایای جنگل تصادفی آن است که هم برای رگرسیون و هم برای دستهبندی قابل استفاده است و راهکاری مناسب برای مشاهده اهمیت نسبی که به ویژگیهای ورودی تخصیص داده میشود است. جنگل تصادفی الگوریتمی بسیار مفید و با استفاده آسان محسوب میشود، زیرا هایپرپارامترهای پیشفرض آن اغلب نتایج پیشبینی خوبی را تولید میکنند. همچنین، تعداد هایپرپارامترهای آن بالا نیست و درک آنها آسان است.
یکی از بزرگترین مشکلات در یادگیری ماشین، بیشبرازش است، اما اغلب اوقات این مساله به آن آسانی که برای دستهبند جنگل تصادفی به وقوع میپیوندد، اتفاق نمیافتد. محدودیت اصلی جنگل تصادفی آن است که تعداد زیاد درختها میتوانند الگوریتم را برای پیشبینیهای جهان واقعی کند و غیر موثر کنند.
به طور کلی، آموزش دادن این الگوریتمها سریع انجام میشود، اما پیشبینی کردن پس از آنکه مدل آموزش دید، اندکی کند به وقوع میپیوندد. یک پیشبینی صحیحتر نیازمند درختان بیشتری است که منجر به کندتر شدن مدل نیز میشود. در اغلب کاربردهای جهان واقعی، الگوریتم جنگل تصادفی به اندازه کافی سریع عمل میکند، اما امکان دارد شرایطهایی نیز وجود داشته باشد که در آن کارایی زمان اجرا حائز اهمیت است و دیگر رویکردها ترجیح داده میشوند. البته، جنگل تصادفی یک ابزار مدلسازی پیشبین و نه یک ابزار توصیفی است. این یعنی، اگر کاربر به دنبال ارائه توصیفی از دادههای خود است، استفاده از رویکردهای دیگر ترجیح داده میشوند.






