ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی
ناب لرنینگ |
بزرگترین بانک اطلاعاتی پروژه های دانشجویی دیتاست واکه ژاپنی
در حال بارگذاری
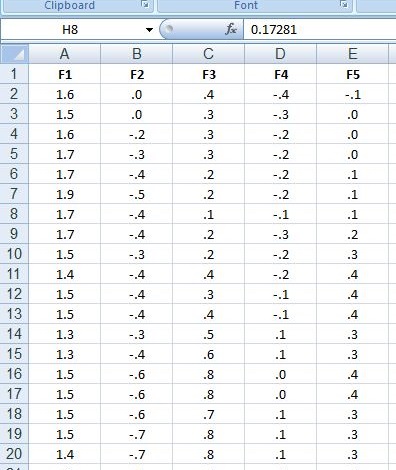
این پروژه مربوط به دیتاست واکه ژاپنی می باشد.
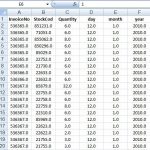
داده ها برای بررسی طبقه بندی جدید به دست آمده برای منحنی های چند بعدی (سری زمانی چند بعدی) جمع آوری شد. نه سخنرانان مرد گفتند: دو واکه ژاپنی/ae/ به طور متوالی. برای هر سخنرانی، با پارامترهای تجزیه و تحلیل شده در زیر شرح داده شده ، ما با استفاده از تجزیه و تحلیل پیش بینی خطی ۱۲ درجه به آن برای به دست آوردن یک سری زمان گسسته با ۱۲ ضریب .LPC cepstrum. این به این معنی است که یک سخنرانی یک سخنران یک سری زمانی را تشکیل می دهد که طول آن در محدوده ۷ تا ۲۹ است و هر نقطه یک سری زمانی از ۱۲ ویژگی (۱۲ ضریب) است.
تعداد سری زمانی ۶۴۰ مجموع است. ما یک مجموعه از ۲۷۰ سری زمانی برای آموزش و مجموعه ای دیگر از ۳۷۰ سری زمانی برای آزمایش استفاده کردیم.
تعداد موارد (نکات):
آموزش: ۲۷۰ (۳۰ سخنرانی توسط ۹ سخنران. فایل size_ae.train را ببینید.)
تست: ۳۷۰ (۲۴-۸۸ سخنرانی های ۹ سخنران در فرصت های مختلف. فایل size_ae.test را ببینید.)
طول سری زمانی:
۷ تا ۲۹ وابسته به سخنان
پارامترهای تحلیل:
* نرخ نمونه برداری: ۱۰ کیلوهرتز
* طول قاب: ۲۵٫۶ میلی ثانیه
* طول شیب: ۶٫۴ مگابایت
* درجه ضریب LPC: 12
فایل ها:
* فایل آموزش: ae.train
* فایل تست: ae.test
فرمت:
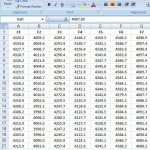
هر خط در ae.train یا ae.test نشان دهنده ۱۲ ضریب LPC در نظم افزایش است که با فضاهای جدا شده است. این مربوط به یک فریم تجزیه و تحلیل است.
خطوط به بلوک ها، مجموعه ای از ۷-۲۹ خط با خطوط خالی جدا شده و به یک گفتار تک گفتار/ae/ با ۷-۲۹ فریم متصل می شوند.
هر سخنران مجموعه ای از بلوک های متوالی است. در ae.train برای هر بلندگو ۳۰ بلوک وجود دارد. بلوک های ۱-۳۰ نشان دهنده بلندگو ۱، بلوک های ۳۱-۶۰ نشان دهنده سخنران ۲، و به همین ترتیب تا بلندگو ۹٫ در آزمون ae، سخنرانان ۱ تا ۹ تعداد بلوک مربوطه: ۳۱ ۳۵ ۸۸ ۴۴ ۲۹ ۲۴ ۴۰ ۵۰ ۲۹٫ بنابراین، بلوک ۱-۳۱ نشان دهنده سخنران ۱ (۳۱ سخنان /ae/ بلوک ۳۲-۶۶ نشان دهنده سخنران ۲ (۳۵ سخنان /ae/ و غیره).
تعداد نمونه ها:
۶۴۰ نمونه
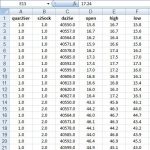
تعداد ویژگی ها:
۱۲ ویژگی
داده های پرت:
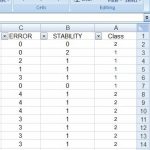
این دیتاست فاقد داده های پرت یاMissing Values می باشد.
امکانات پروژه دیتاست واکه ژاپنی :
- این دیتاست دارای یک داکیومنت کامل فارسی است. در این داکیومنت عنوان دیتاست، توضیحات کامل دیتاست، تعداد ویژگی ها، تعداد نمونه ها، توضیح تمام ویژگی های موجود و لینک دیتاست تشریح شده است.
- این دیتاست دارای یک داکیومنت کامل انگلیسی نیز می باشد، که در این دیتاست اطلاعات کاملی به زبان لاتین در رابطه با دیتاست معرفی شده ارائه شده است.
- پس از خرید، امکان دانلود فایل اصلی دیتاست در قالب فایل اکسل میسر است.
- فایل پیش پردازش دیتاست
- وجود فایل ARFF و قابل اجرا در نرم افزار داده کاوی مثل وکا
- امکان دانلود لینک دیتاست در یک فایل متنی به صورت جداگانه
نکته: برای این دیتاست انواع الگوریتم های داده کاوی اهم از ۱۴۷ الگوریتم دسته بندی (مثل: درخت تصمیم، شبکه عصبی، ماشین بردار پشتیبان و …)، ۶ الگوریتم خوشه بندی (مثل: K-Means ، DBSCAN ،X-Means و…)، ۳ الگوریتم انجمنی (مثل Apriori ، FP-Growth و …) و چندین الگوریتم انتخاب ویژگی (مثل PSO و …) با استفاده از ابزارهای داده کاوی و برنامه نویسی اهم از رپیدماینر، وکا، تاناگرا، SPSS، مدلر، کلمنتاین، متلب و … تهیه و پیاده سازی شده است.
- لینک دانلود فایل بلافاصله پس از پرداخت وجه نمایش داده می شود.
- همچنین لینک دانلود به ایمیل شما ارسال خواهد شد به همین دلیل ایمیل خود را به دقت وارد نمایید.
- ممکن است ایمیل ارسالی به پوشه اسپم یا Bulk ایمیل شما ارسال شده باشد.
- در صورتی که به هر دلیلی موفق به دانلود فایل مورد نظر نشدید کافیست به ایمیل سایت درخواستتان را ارسال نمایید.
- حدود 90% از پروژه ها دارای داکیومنت و فیلم آموزشی می باشند.